
《深入理解 Java 虚拟机》学习笔记
第一部分 走进 Java
第 1 章 走进 Java
1.1 概述
Java 语言口号是:一次编写,到处运行!
Java 的优点:结构严谨、面向对象;摆脱平台的束缚,一次编写到处运行;提供了相对安全的内存管理和访问机制;实现了热点代码检测和运行时编译及优化;一套完善的应用程序接口以及无数的第三方类库
1.2 Java 技术体系
Sun 定义的 Java 技术体系包括:Java 程序设计语言、各种硬件平台的 Java 虚拟机、Class 文件格式、Java API 类库、来自商业机构和开源社区的第三方 Java 类库。
JDK 是支持 java 开发的最小的环境,包括:Java 程序设计语言、Java 虚拟机、Java API 类库三个部分;JRE 是 JavaAPI 中的 Java SE API 的子集和 Java 虚拟机这两部分。
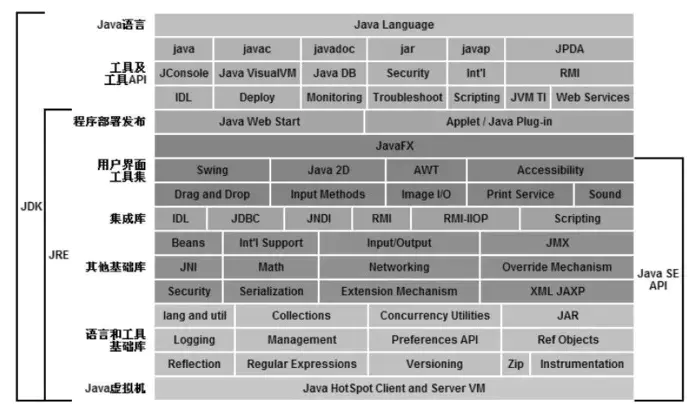
Java 技术体系可分为 4 个平台:Java Card、Java ME、Java SE、Java EE
1.3 Java 发展史
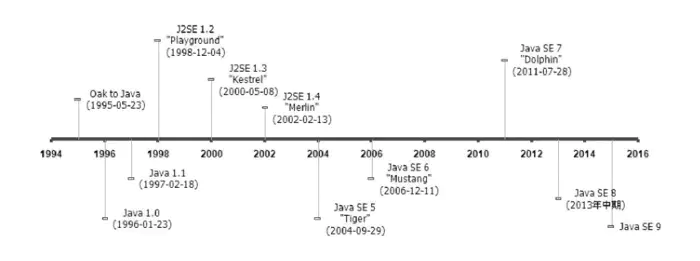
Java 语言的前身是 Oak,起源于 1991 年 4 月的 James Gosling 博士的绿色计划。
1995.5.23 Oak 改名为 Java,并发布 Java 1.0 版本,提出口号。
1996.1.23 JDK 1.0 发布,提供了 JVM 的实现,Applet、AWT 等;
1997.2.19 Sun 发布 JDK1.1,提供了 JAR、JDBC、JavaBean、RMI,java 语法的发展例如,内部类、反射等;
1998.12.4 JDK1.2,将 java 技术体系划分为 3 个方向:J2ME、J2SE、J2EE
1999.4.27 HotSpot 虚拟机发布,随 JDK1.2 发布,作为 1.3 之后的默认虚拟机。
2000.5.8 JDK1.3,
2002.2.13 JDK1.4,正则表达式、异常连、NIO、日志类等
2004.9.30 JDK1.5,自动拆箱装箱、泛型、动态注解、枚举、可变长参数、foreach 循环等,虚拟机改进了 JMM, 提供变法包等
2006.12.11 JDK1.6,提供编译 API、微型 HTTP 服务器 API 等,虚拟机改进了锁与同步、垃圾收集、类加载等
2012.10.16 Java SE7 Update9 发布,提供 G1 收集器等
2013.9 JDK1.8 发布,提供 Lambda 表达式。
1.4 Java 虚拟机发展史
Sun Classic/Exact VM、Sun HotSpot VM、Sun Mobile-Embedded VM/Meta-Circular VM 、BEA JRockit/IBM J9 VM 、Azul VM/BEA Liquid VM、还有很多……
1.5 展望 Java 技术的未来
模块化、混合语言、多核并行、进一步丰富语法、64 位虚拟机
1.6 实战:自己编译 JDK
下载 OpenJDK:https://jdk7.java.net/source.html
系统需求:Ubuntu 64 位、5GB 的磁盘、1G 内存;
构建编译环境:需要 Bootstrap JDK(JDK6 以上)/Ant(1.7.1 以上)/GCC。
进行编译:设置环境变量、make sanity 检查、make 编译、复制到 JAVA_HOME、编辑 env.sh
1.7 本章小结
本章介绍了 Java 技术体系的过去、现在以及未来的一些发展趋势,并独立编译一个 OpenJDK 7 的版本。
第二部分 自动内存管理机制
第 2 章 Java 内存区域与内存溢出异常
2.1 概述
Java 与 C++ 之间有一面内存动态分配和垃圾收集技术所围成的墙。对于 Java 程序员来说,在虚拟机自动内存管理机制下,不需要为 new 操作去写配对的 delete/free 代码,不容易出现内存泄漏。但是如果出现内存泄漏问题,如果不了解虚拟机的机制,便难以定位。
2.2 运行时数据区域
Java 虚拟机在执行 Java 程序的过程中会把它所管理的内存划分为若干个不同的数据区域,主要包括以下几个运行时数据区域:

1)程序计数器
程序计数器是当前线程所执行字节码的行号指示器。在虚拟机概念模型中,字节码解释器的工作是通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成。该部分内存区域是 _线程私有_ 的内存。如果线程正在执行的是 Java 方法,这个程序计数器记录的是正在执行的虚拟机字节码指定的地址;如果是正在执行 Native 方法,这个程序计数器值为空。
此内存是唯一一个在 java 虚拟机规范中没有规定 OutOfMemoryError 情况的区域。
2)Java 虚拟机栈
该区域也是 _ 线程私有 _ 的,其生命周期与线程相同。虚拟机栈描述的是 Java 方法执行的内存模型:每个方法在执行时都会创建一个栈帧用于存 _局部变量表、操作数栈、动态链接、方法出口等_ 信息。每个方法的调用到执行完成,就对应着一个栈帧在虚拟机栈中的入栈出栈的过程。
局部变量存放编译器可知的基本类型数据(boolean、byte、char、short、int、float、long、double)、对象引用、returnAddress 类型。其中 64 位的 long 和 double 占 2 个局部变量空间(slot),其余占 1 个。局部变量表所需的空间在编译期间完成分配。
Java 虚拟机规范对该区域规定了 StackOverflowError 异常和 OutOfMemoryError 异常。
3)本地方法栈
本地方法栈为虚拟机执行 Native 方法服务的,是 _线程私有_ 的内存区域。Java 虚拟机规范没有规定本地方法栈使用的语言、使用方式与数据结构。Sun HotSpot 直接将本地方法栈和虚拟机栈合二为一。
Java 虚拟机规范对该区域规定了 StackOverflowError 异常和 OutOfMemoryError 异常。
4)Java 堆
Java 堆是 **线程共享** 的,是 java 虚拟机管理的最大一块内存,在虚拟机启动时创建。该区域存放所有的 _对象实例以及数组_。Java 堆是垃圾回收器管理的主要区域。从内存回收角度,现在收集器采用分分代收集算法,将 Java 堆分为新生代和老年代;再细致点将新生代分为 Eden 空间、From Survivor 空间和 To Survivor 空间等。从内存分配角度,线程共享的 java 堆可能划分多个线程私有的分配缓冲区(Thread Local Allocation Buffer,TLBA)。Java 虚拟机规范规定,Java 堆可以处于物理上不连续的内存空间,只要逻辑上连续即可。可通过 -Xmx 和 -Xms 进行控制堆内存大小。
Java 虚拟机规范对该区域规定了 OutOfMemoryError 异常。
5)方法区
该区域是 **线程共享** 的,用于存储已被加载的 _类信息、常量、静态变量、即时编译器编译后的代码_ 等数据。尽管 Java 虚拟机规范规定该区域是堆的一个逻辑部分,但是它的别名叫 Non-Heap(非堆),目的是与 Java 堆区分开。对于习惯 HotSpot 虚拟机开发、部署的开发者来说,将方法区成为永久代。不需要连续的内存空间,可以设置内存大小,还可以选择不同的垃圾收集。永久代用 -XX:MaxPermSize 设置。
Java 虚拟机规范对该区域规定了 OutOfMemoryError 异常。
6)运行时常量池
运行时常量池是方法区的一部分,Class 文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息是常量池,用于存放编译器生成的各种 _字面量和符号引用,这部分内容将在类加载后进入方法区的运行时常量池中存放。除了保存 Class 文件描述的符号引用外,还把翻译出来的直接引用_ 存在运行时常量池。另外一个重要特征是具备动态性,可以在运行期间将新的常量放入池中,如 String 的 intern 方法。
Java 虚拟机规范对该区域规定了 OutOfMemoryError 异常。
7)直接内存
直接内存不是虚拟机运行时数据区的一部分,也不是 Java 虚拟机规范中定义的内存区域。JDK 1.4 的 NIO 引入了基于通道(Channel)和缓冲区(Buffer)的 IO 方法,可以使用 Native 函数库直接分配对外内存,然后通过一个存储在 Java 堆中的 DirectByteBuffer 对象作为这块内存的引用进行操作以提升性能。
2.3 HotSpot 虚拟机对揭秘
为了进一步了解虚拟机内存中数据的其他细节,比如它们是如何创建、如何布局以及如何访问的。下面以虚拟机 HotSpot 和常用的内存区域 Java 堆为例,深入探讨 HotSpot 虚拟机在 Java 堆中对象分配、布局和访问的全过程。
1. 对象的创建
** (1)** 虚拟机遇到一条 new 指令时,先检查指令的参数是否能在常量池中定位到一个类的符号引用,并且检查这个符号引用代表的类是否已被加载、解析和初始化过。如果没有,那必须先执行相应的类加载过程。
(2) 在类的加载检查后,接下来虚拟机为对象分配内存空间。对象所需的内存大小在类加载完成后便可确定。虚拟机可以采取“指针碰撞”或者“空闲列表”进行内存分配,选择哪种分配方法取决于 Java 堆是否规整,而 java 堆是否规整又由所采取的垃圾回收器是否带压缩整理功能决定。因此,Serial、ParNew、等带 Compact 过程的收集器采用指针碰撞分配,CMS 采用空闲列表。在并发情况下,在对象分配内存时要注意同步。解决该问题有 2 种方案:一种是对分配内存空间动作进行同步处理——虚拟机采用 CAS 配上失败重试方式保证原子性;另一种是不内存分配动作按照线程划分为不同的空间进行,即每个线程在 Java 堆中预先分配一小块内存(TLAB), 可通过 -XX:+/UseTLAB 设定。
**(3)** 内存分配完后,虚拟机将分配到的内存空间都初始化为零值(不包括对象头),如果使用了 TLAB,初始化工作是在 TLAB 分配时进行的。这保证了对象的实例字段在 Java 代码中可以不赋值就直接使用,程序能访问到这些字段数据类型对应的零值。
**(4)** 接下来虚拟机要对对象进行必要的设置,即设置对象的对象头(Object Header)信息,包括对象是哪个类的实例、如何才能找到类的元数据信息、对象的哈希码、对象 GC 分代年龄等信息。
**(5)** 在上面的工作完成后,从虚拟机角度来看,一个新对象产生了,但是从 Java 程序角度来看,对象创建才刚刚开始。——方法还没执行,所有字段还是零。接着执行方法,把对象按照程序员的意愿进行初始化,这样一个真正可用的对象才算完全产生出来;
HotSpot 解释器的代码片段:略
2. 对象的内存布局
在 HotSpot 虚拟机中,对象在内存中的存储布局分为 3 块区域:对象头(Header)、实例数据(Instance Data)、对其填充(Padding)。
1. 对象头
HotSpot 虚拟机的对象头包括 2 部分信息:
第一部分用于存储对象自身运行时数据(如哈希吗、GC 分代年龄、锁状态标志、线程持有的锁、偏向线程 ID、偏向时间戳等),叫做“Mark Word”。
第二部分是类型指针,即对象指向它的类元数据的指针,虚拟机可以通过这个指针确定对象时哪个类的实例(并不是所有虚拟机都必须在对象数据上保留类型指针)。若是 Java 的数组,对象头中还要有一块存储数组长度的数据,因为虚拟机可以通过普通对象的元数据信息确定 Java 对象的大小,但是从数组的元数据中无法确定数组的大小。
2. 实例数据
是对象真正存储的有效信息,就是代码中所定义的各种类型字段的内容。不论是父类继承还是子类中定义的都要记录起来。HotSpot 虚拟机默认分配策略:longs/doubles ints shorts/chars bytes/booleans oops(Ordinary Object Pointers),相同的字段总是分配在一起,在满足这个条件的情况下父类中定义的变量会出现在子类前。
** 3. 对其填充 **
不是必然存在的,没有特别含义,起到占位符的作用。由于 HotSpot VM 自动内存管理系统要求对象的起始地址是 8 字节的整数倍,即对象的大小是 8 字节的整数倍。对象头正好是 8 字节整数倍,但是实例数据没有对齐时,使用该字段对齐。
3. 对象的访问定位
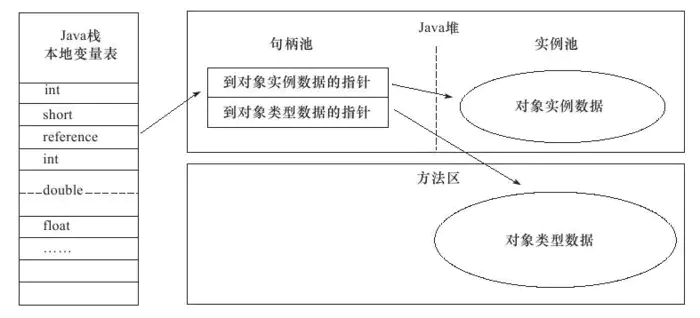
Java 程序中需要通过栈中的 reference 数据操作堆上的具体对象。目前主流的访问方式有 _使用句柄_ 和 **直接指针**。
1. 使用句柄
Java 堆中划分出一块内存作为句柄池,reference 中存储的是对象的句柄地址,而句柄中包含了对象实例数据与类型数据各自的具体地址信息。
2. 直接访问对象
如果使用直接指针访问,那么 Java 堆对象分布中就必须考虑如何放置访问类型数据的相关信息,reference 存储的直接就时对象地址。
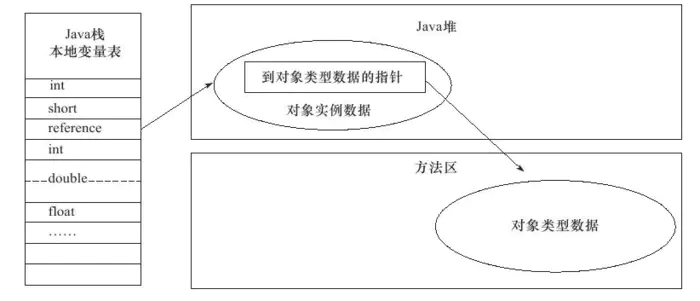
这两种对象的访问方式各有优势,使用句柄访问最大的好处就是 reference 中存储的是稳定的句柄地址,在对象被移动时,只用修改句柄中的实例数据指针,而 reference 本身不需要修改。而直接访问对象方式的好处就是,减少一次指针定位的时间开销,由于对象的访问是非常频繁的,因此这类开销积少成多也是一项非常的执行成本。HotSpot 使用的是第二种方式。
2.4 OutOfMemoryError 异常
在 Java 虚拟机规范中,除了程序计数器之外,其他几个运行时区域都有发生 OOM 异常的可能。本节目的有二:
通过代码验证 Java 虚拟机规范中描述各个运行时区域存储的内容;
在实际遇到内存溢出异常时,能根据异常的信息快速判断是哪个区域内存溢出以及怎么处理。
1. Java 堆溢出
Java 堆用于存储对象实例,只要不断创建对象,并且保证 GC Roots 到对象之间有可达路径来避免垃圾回收机制清除这些对象,那么在对象数量达到最大堆的容量限制之后就会产生内存溢出异常。
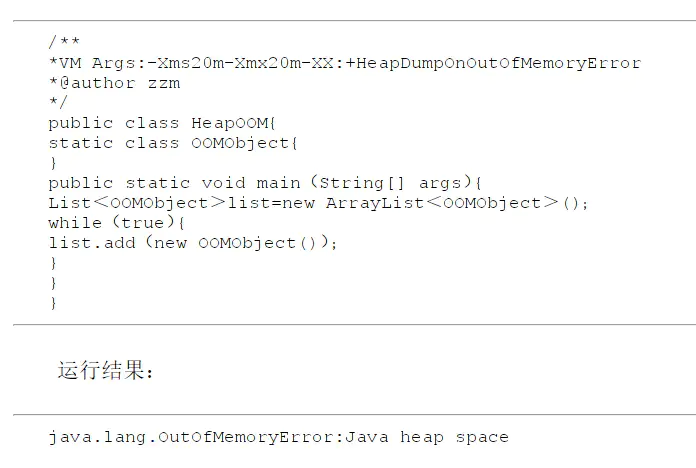
解决思路:先通过内存映像分析工具对 dump 出来的堆转储快照进行分析,先分清楚是内存泄漏还是内存溢出;如果是内存泄漏,进一步查看泄漏对象到 GC Roots 的引用链,从而确认为什么无法回收;如果是内存溢出,则应当检查虚拟机堆参数(-Xmx 与 -Xmx)或检查是否存在对象生命周期过长、持有状态时间过长的情况。
2. 虚拟机栈和本地方法栈溢出
HotSpot 不区分虚拟机栈和本地方法栈。栈的容量只由 -Xss 参数设置。关于虚拟机栈和本地方法栈,在 Java 虚拟机规范中描述了两种异常:StackOverflowError 和 OutOfMemoryError。

虚拟机栈溢出
虚拟机的默认参数对于通常的方法调用(1000~2000 层)完全够用,通常根据异常的堆栈日志就可以很容易定位问题。
3. 方法区和运行时常量池溢出
对于这个区域的测试,基本思路是运行时产生大量的类去填满方法区(比如使用反射和动态代理),这里我们借助 CGLib 直接操作字节码运行时产生大量的动态类(很对主流框架如 Spring、Hibernate 都会采用类似的字节码技术)。在这里需要特别注意垃圾回收的状况。

借助 CGLib 使方法区出现内存溢出异常 1

借助 CGLib 使方法区出现内存溢出异常 2
4. 本机直接内存溢出
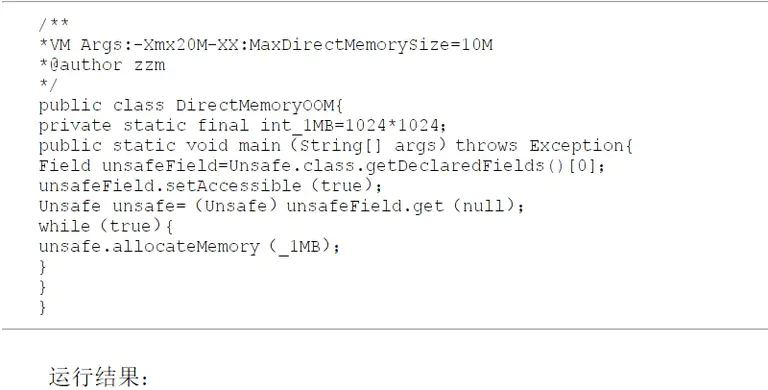
本机直接内存溢出 1

本机直接内存溢出 2
DirectMemory 导致的内存溢出,在 Heap Dump 里不会看见明显的异常。如果发现 OouOfMemory 之后 Dump 文件很小,程序又使用了 NIO,那就可以检查下是否这方面的原因。
2.5 本章小结
学习了虚拟机的内存是如何划分的,对象是如何创建、布局和访问的,哪部分区域、什么样的代码和操作可能导致内存的溢出异常。
第 3 章 垃圾收集器与内存分配策略
3.1 概述
Java 程序通过 reference 类型数据操作堆上的具体对象. 在 JVM 层面的引用 reference 类型是引用类型(Reference Types)的一种;JVM 规范规定 reference 类型来表示对某个对象的引用,可以想象成类似于一个指向对象的指针;对象的操作、传递和检查都通过引用它的 reference 类型的数据进行操作。在 Java 语言层面的引用如果 reference 类型的数据中存储的数值代表的是另外一块内存的起始地址,就称这块内存代表着一个引用。
3.2 对象已死吗
在垃圾收集器进行回收前,第一件事就是确定这些对象哪些还存活,哪些已经死去。
1、引用计数算法
引用计数算法是在对象中添加一个引用计数器,每当有一个地方引用它,计数器就加 1;当引用失效,计算器值就减 1;任何时刻计数器的值为 0 时该对象就是不可用的。
该方法实现简单,判定效率也很高。但是,java 虚拟机中没有使用该方法,其中最主要的原因是该方法不能解决对象之间相互循环引用的问题。
2. 可达性分析算法
该算法基本思想是:通过一系列被称为“GC Roots”的对象作为起始点,从该起始点开始向下搜索,搜索所走过的路径叫做引用链,当一个对象到 GC Roots 没有任何引用链时,则证明该对象是不可用的。
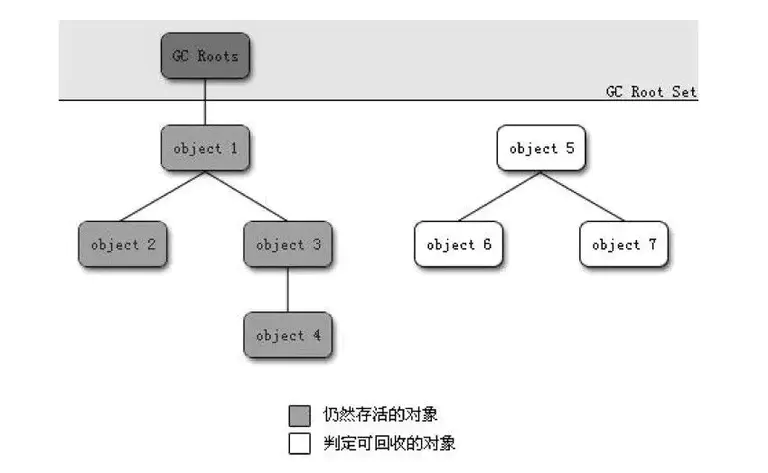
在 Java 中,可作为 GC Roots 对象包括:虚拟机栈(栈帧的本地变量表)中引用的对象、方法区中类静态属性引用的对象、方法区中常量引用的对象、本地方法栈中 JNI(一般说的 Native 方法)引用的对象。
3. 再谈引用
JDK 1.2 将 Java 的引用分为:强引用、软引用、弱引用、虚引用 4 种,强度依次减弱。
强引用:就是常见的引用,类似 Object o=new Object() 这类引用,只要强引用存在,垃圾收集器永远不会回收被引用的对象。
** 软引用:** 描述一些还有用但非必需的对象。软引用关联的对象,在系统将要发生内存溢出之前,将会把这些对象列进回收范围之中进行第二次回收。如果这次回收没有足够的内存,才会发生内存溢出异常。提供 SoftReference 类实现软引用。
弱引用: 也用来描述非必需的对象,比软引用还要弱。该引用引用的对象只能生存到下一次垃圾收集器发生之前。当垃圾回收器工作时,不论内存是否足够都会回收被弱引用引用的对象。提供 WeakReference 类实现弱引用。
虚引用:又称幽灵引用或者幻影引用,最弱的引用关系。一个对象是否有该引用存在,完全不会对其生存时间构成影响,也无法通过该引用获得一个对象实例。唯一目的是:能在这个对象再被收集器回收时收到一个系统通知。提供 PhantomReference 类实现虚引用。
4. 对象生存还是死亡
要真正宣告一个对象死亡,至少要经历两次标记过程:
第一次标记:如果对象在进行可达性分析后发现到 GC Roots 没有任何引用链相连时,那么它将被第一次标记并且进行一次筛选,筛选的条件是此对象是否必要执行 finalize()方法。当对象没有覆盖 finalize() 方法或者 finalize() 方法已经被 JVM 调用过,虚拟机认为这两种情况都是没必要执行,可以认为对象已死,可以回收。如果对象被判定有必要执行 finalize()方法,那么这个对象将会被放入 F-Queue 队列中,并在稍后由一个由 JVM 自动建立的、低优先级的 Finalizer 线程执行它。
第二次标记:finalize()方法是对象逃脱死亡的最后一次机会,GC 将对 F-Queue 队列中的对象进行第二次小规模标记。如果对象在其 finalize() 方法中重新与引用链上任何一个对象建立关联,第二次标记时会将其移出 "即将回收" 的集合;如果对象没有逃脱,也可以认为对象已死,可以回收了。
一个对象的 finalize()方法只会被系统自动调用一次,经过 finalize() 方法逃脱死亡的对象,第二次不会再调用。
5. 回收方法区
方法区(HotSpot 叫永久代)的垃圾回收主要回收:废弃常量和无用的类。
判定废弃常量比较简单,但是判定无用类比较苛刻。类要同时满足下面 3 个条件才能算无用的类:
1)该类的所有实例都被回收,就是 java 堆中不存在该类的任何实例
2)加载该类的 ClassLoader 已经被回收
3)该类的 java.lang.Class 对象没有被任何地方引用,无法在任何地方通过反射访问该类的方法
在大量使用反射、动态代理、CGLib 等 ByteCode 框架、动态生成 JSP 以及 OSGI 这类频繁自定义 ClassLoader 的场景都需要虚拟机具备类卸载的功能(HotSpot 提供 -Xnoclassgc 参数控制),以保证永久代不会溢出。
3.3. 垃圾收集算法
1、标记 - 清除算法
该算法分为“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收掉所有被标记的对象。
它的主要缺点有两个:一个是 _ 效率问题 _,标记和清除过程的效率都不高;另外一个是 _ 空间问题 _,标记清除之后会产生大量不连续的内存碎片,空间碎片太多可能会导致,当程序在以后的运行过程中需要分配较大对象时无法找到足够的连续内存而不得不提前触发另一次垃圾收集动作。
2、复制算法
为了解决效率问题,一种称为“复制”(Copying)的收集算法出现了,它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。这样使得每次都是对其中的一块进行内存回收,内存分配时也就不用考虑内存碎片等复杂情况,只要移动堆顶指针,按顺序分配内存即可,实现简单,运行高效。只是这种算法的代价是将内存缩小为原来的一半,未免太高了一点。
现在的商业虚拟机都采用这种收集算法来回收新生代,新生代中的对象 98% 是朝生夕死的,所以并不需要按照 1∶1 的比例来划分内存空间,而是将内存分为一块较大的 Eden 空间和两块较小的 Survivor 空间,每次使用 Eden 和其中的一块 Survivor。当回收时,将 Eden 和 Survivor 中还存活着的对象一次性地拷贝到另外一块 Survivor 空间上,最后清理掉 Eden 和刚才用过的 Survivor 的空间。HotSpot 虚拟机默认 Eden 和 Survivor 的大小比例是 8∶1,也就是每次新生代中可用内存空间为整个新生代容量的 90%(80%+10%),只有 10% 的内存是会被“浪费”的。当然,98% 的对象可回收只是一般场景下的数据,我们没有办法保证每次回收都只有不多于 10% 的对象存活,当 Survivor 空间不够用时,需要依赖其他内存(这里指老年代)进行分配担保(Handle Promotion)。
3、标记 - 整理算法
复制收集算法在对象存活率较高时就要执行较多的复制操作,效率将会变低。更关键的是,如果不想浪费 50% 的空间,就需要有额外的空间进行分配担保,以应对被使用的内存中所有对象都 100% 存活的极端情况,所以在老年代一般不能直接选用这种算法。根据老年代的特点,有人提出了另外一种“标记 - 整理”(Mark-Compact)算法,标记过程仍然与“标记 - 清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。
4、分代收集算法
当前商业虚拟机的垃圾收集都采用“分代收集”(Generational Collection)算法,一般是把 Java 堆分为新生代和老年代。在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集。而老年代中因为对象存活率高、没有额外空间对它进行分配担保,就必须使用“标记 - 清理”或“标记 - 整理”算法来进行回收。
3.4 HotSpot 的算法实现
1. 枚举根节点
由于可达性分析的 GC Roots 节点主要在全局性的引用 (例如常量或类静态属性) 与执行上下文 (例如栈帧中的本地变量表) 中 ,如果要逐个检查这里面的引用, 那么必然会消耗很多时间。另外,可达性分析对执行时间的敏感还体现在 GC 停顿上 , 因为这项分析工作必须在一个能确保一致性的快照中进行,从而导致 GC 进行时必须要停顿所有 Java 执行线程。
由于目前的主流 Java 虛拟机使用的都是准确式 GC , 所以当执行系统停顿下来后, 并不需要一个不漏地检查完所有执行上下文和全局的引用位置, 虚拟机应当是有办法直接得知哪些地方存放着对象引用。在 HotSpot 的实现中, 是使用一组称为 OopMap 的数据结构来达到这个目的的, 在类加载完成的时候 ,HotSpot 就把对象内什么偏移量上是什么类型的数据计算出来, 在 JIT 编译过程中, 也会在特定的位置记录下栈和寄存器中哪些位置是引用。这样 ,GC 在扫描时就可以直接得知这些信息了。
2. 安全点
HotSpot 只在特定的位置记录了 OopMap,这些位置称为安全点(SafePoint);
即程序执行时并非在所有地方都能停顿下来开始 GC,只有到达安全点时才能暂停;
对于安全点基本上是以程序“是否具有让程序长时间执行的特征”(比如方法调用、循环跳转、异常跳转等)为标准进行选定的;
另外还需要考虑如果在 GC 时让所有线程都跑到最近的安全点上,有两种方案:抢先式中断和主动式中断(主流选择);
3、安全区域
如果程序没有分配 CPU 时间(如线程处于 Sleep 或 Blocked),此时就需要安全区域(Safe Region),其是指在一段代码片段之中,引用关系不会发生变化。线程执行到安全区域时,首先标识自己已经进入了安全区域,这样 JVM 在 GC 时就不管这些线程了;
3.5 垃圾收集器
如果两个收集器之间存在连线,就说明它们可以搭配使用。
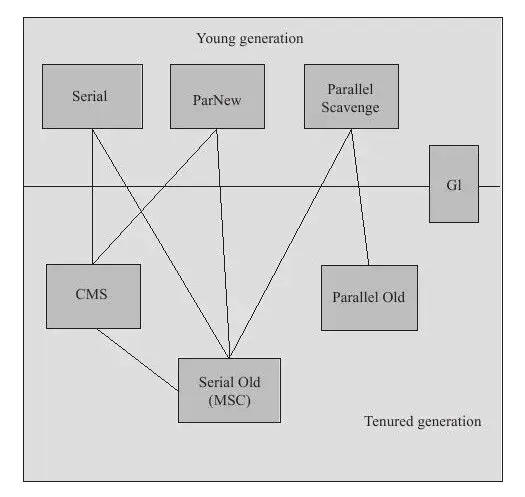
1、Serial 收集器
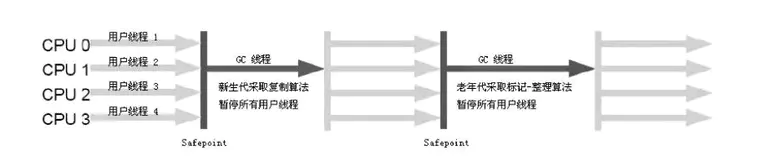
** 特点:** 最基本、发展历史最悠久,在 JDK 1.3 之前是新生代收集的唯一选择;是一个单线程(并非指一个收集线程,而是会暂停所有工作线程)的收集器,采用的是复制算法;现在依然是虚拟机运行在 Client 模式下的默认新生代收集器,主要就是因为它简单而高效(对于限定单个 CPU 的环境来说,没有线程交互的开销);
2、ParNew 收集器
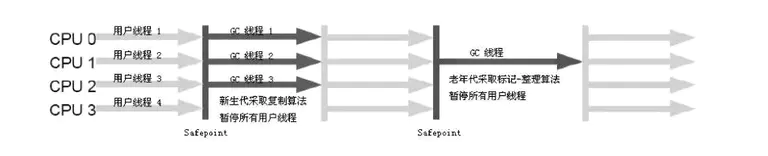
** 特点:**ParNew 收集器其实就是 Serial 收集器的多线程版本,除了使用多条线程进行垃圾收集之外,其余行为包括 Serial 收集器可用的所有控制参数(例如:-XX:SurvivorRatio、 -XX:PretenureSizeThreshold、-XX:HandlePromotionFailure 等)、收集算法、Stop The World、对象分配规则、回收策略等都与 Serial 收集器完全一样,实现上这两种收集器也共用了相当多的代码。
ParNew 收集器是许多运行在 Server 模式下的虚拟机中首选的新生代收集器,其中有一个与性能无关但很重要的原因是,除了 Serial 收集器外,目前只有它能与 CMS 收集器配合工作。
3、ParallelScavenge 收集器
** 特点:** 新生代收集器,使用复制算法,并行的多线程收集器;与其他收集器关注于尽可能缩短垃圾收集时用户线程停顿时间不同,它的目标是达到一个可控制的吞吐量;高吞吐量可以高效率利用 CPU 时间,适合在后台运算而不需要太多交互的任务;Parallel Scavenge 收集器提供了两个参数用于精确控制吞吐量,分别是控制最大垃圾收集停顿时间的 -XX:MaxGCPauseMillis 参数及直接设置吞吐量大小的 -XX:GCTimeRatio 参数,而停顿时间缩短是以牺牲吞吐量和新生代空间来换取的;另外它还支持 GC 自适应的调节策略。
4、Serial Old 收集器
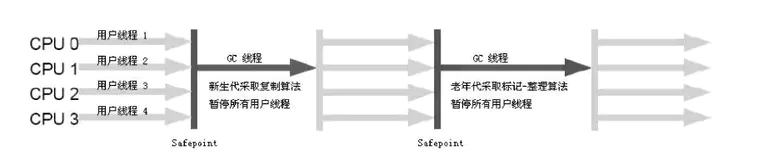
** 特点:** 是 Serial 收集器的老年代版本,同样是单线程,使用标记 - 整理算法;主要是给 Client 模式下的虚拟机使用的;在 Server 模式下主要是给 JDK 1.5 及之前配合 Parallel Scavenge 使用或作为 CMS 收集器的后备预案;
5、Parallel Old 收集器
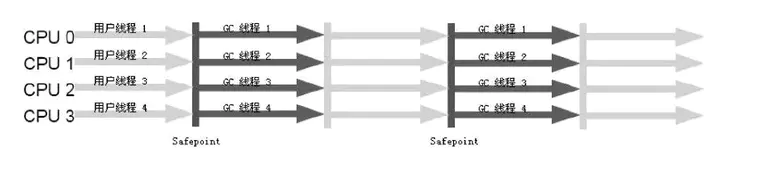
** 特点 **:Parallel Old 是 ParallelScavenge 收集器的老年代版本,使用多线程和“标记-整理”算法。直到 Parallel Old 收集器出现后,“吞吐量优先”收集器终于有了比较名副其实的应用组合,在注重吞吐量及 CPU 资源敏感的场合,都可以优先考虑 Parallel Scavenge 加 Parallel Old 收集器。
6、CMS 收集器
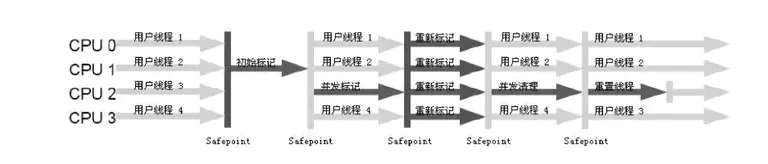
CMS(Concurrent MarkSweep)收集器是一种以获取最短回收停顿时间为目标的收集器。目前很大一部分的 Java 应用都集中在互联网站或 B/S 系统的服务端上。从名字(包含“Mark Sweep”)上就可以看出 CMS 收集器是基于“标记 - 清除”算法实现的,整个过程分为 4 个步骤,包括:初始标记(CMS initial mark)、并发标记(CMS concurrent mark)、重新标记(CMS remark)、并发清除(CMS concurrent sweep)
其中初始标记、重新标记这两个步骤仍然需要“Stop The World”。初始标记仅仅只是标记一下 GC Roots 能直接关联到的对象,速度很快,并发标记阶段就是进行 GC Roots Tracing 的过程,而重新标记则是为了修正并发标记期间,因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录。由于整个过程中耗时最长的并发标记和并发清除过程中,收集器线程都可以与用户线程一起工作,所以总体上来说,CMS 收集器的内存回收过程是与用户线程一起并发地执行的。
CMS 有以下三个显著的缺点:CMS 收集器对 CPU 资源非常敏感。CMS 收集器无法处理浮动垃圾(FloatingGarbage),可能出现“Concurrent Mode Failure”失败而导致另一次 Full GC 的产生。CMS 是一款基于“标记 - 清除”算法实现的收集器,这意味着收集结束时会产生大量空间碎片。
7 、G1 收集器
G1 是一款面向服务端应用的垃圾收集器,后续会替换掉 CMS 垃圾收集器;
特点:并行与并发(充分利用多核多 CPU 缩短 Stop-The-World 时间)、分代收集(独立管理整个 Java 堆,但针对不同年龄的对象采取不同的策略)、空间整合(基于标记 - 整理)、可预测的停顿(将堆分为大小相等的独立区域,避免全区域的垃圾收集);
关于 Region:新生代和老年代不再物理隔离,只是部分 Region 的集合;G1 跟踪各个 Region 垃圾堆积的价值大小,在后台维护一个优先列表,根据允许的收集时间优先回收价值最大的 Region;Region 之间的对象引用以及其他收集器中的新生代与老年代之间的对象引用,采用 Remembered Set 来避免全堆扫描;
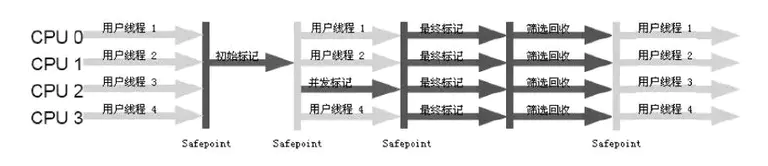
如果不计算维护 Remembered Set 的操作,G1 收集器的运作大致可划分为以下几个步骤:
初始标记(Initial Marking):并行,仅仅只是标记一下 GC Roots 能直接关联到的对象,并且修改 TAMS(Next Top at Mark Start)的值,让下一阶段用户程序并发运行时,能在正确可用的 Region 中创建新对象,这阶段需要停顿线程,但耗时很短;
** 并发标记(Concurrent Marking)**:并发,从 GC Root 开始对堆中对象进行可达性分析,找出存活的对象,这阶段耗时较长;
最终标记(Final Marking):并行,为了修正在并发标记期间因用户程序继续运作而导致标记产生变动的那一部分标记记录,虚拟机将这段时间对象变化记录在线程 Remembered Set Logs 里面,需要把 Remembered Set Logs 的数据合并到 Remembered Set 中,这阶段需要停顿线程,停顿时间一般会比初始标记阶段稍长一些,但远比并发标记的时间短;
筛选回收(Live Data Counting and Evacuation):并行,首先对各个 Region 的回收价值和成本进行排序,然后根据用户所期望的 GC 停顿时间来制定回收计划。这个阶段其实也可以做到与用户程序一起并发执行,但是因为只回收一部分 Region,时间是用户可控制的,而且停顿用户线程将大幅提供收集效率;
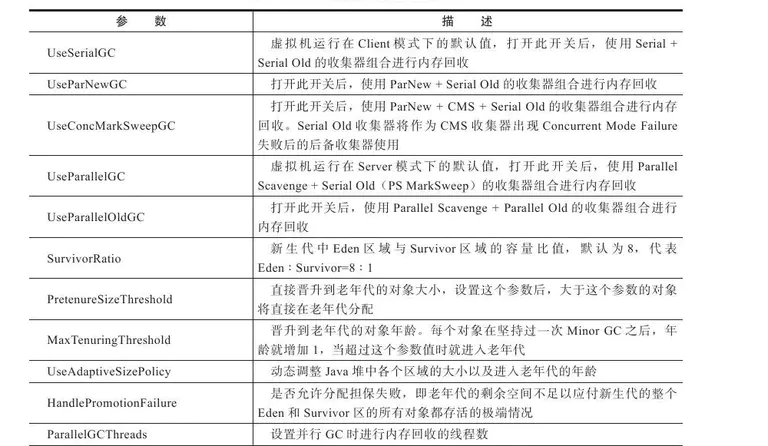
8. 垃圾收集器参数总结

3.6 内存分配与回收策略
对象优先在新生代分配;
大对象直接进入老年代;
长期存活的对象将进入老年代;
动态对象年龄判断(如果在 Survivor 空间中相同年龄所有对象大小总和大于 Survivor 空间的一半,大于或等于该年龄的对象直接进入老年代);
空间分配担保(发生 Minor GC 前,虚拟机会先检查老年代最大可用连续空间是否大于新生代所有对象总空间,如果不成立,虚拟机会查看 HandlePromotionFailure 设置值是否允许担保失败,如果允许继续检查老年代最大可用的连续空间是否大于历次晋升到老年代的平均大小,如果大于会尝试进行一次 Minor GC;如果小于或者不允许冒险,会进行一次 Full GC)
3.7 本章小结
本章介绍了垃圾回收算法、几款 JDK 1.7 中提供的垃圾收集器特点以及运作原理。内存回收与垃圾收集器在很多时候都是影响系统性能、并发能力的主要因素之一,然而没有固定收集器和参数组合,也没有最优的调优方法,需要根据实践了解各自的行为、优势和劣势。
第 4 章 虚拟机性能监控与故障处理工具
4.1 概述
给一个系统 定位问题时,知识和经验是关键基础、数据(运行日志、异常堆栈、GC 日志、线程快照、堆转储快照)是依据、工具是运用知识处理数据的手段。
4.2 JDK 的命令行工具
Sun JDK 监控和故障处理工具:

1、jps: 虚拟机进程状况工具
jps 工具主要选项:


2、jstat: 虚拟机统计信息监视工具
jstat 工具主要选项:


3、jinfo:Java 配置信息工具

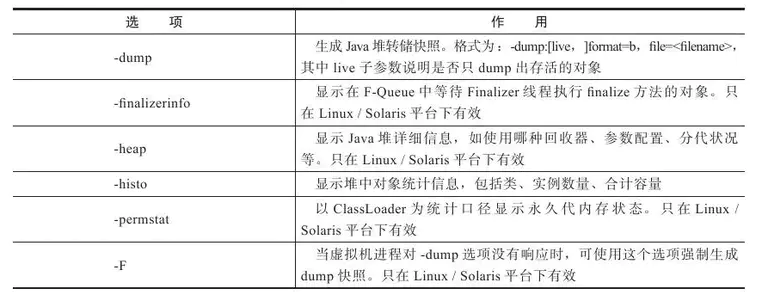
4、jmap:Java 内存映像工具
jmap 工具主要选项:
5、jhat:虚拟机堆转储快照分析工具
6、jstack:Java 堆栈跟踪工具

7、HSDIS:JIT 生成代码反编译


现代虚拟机的实现慢慢地和虚拟机规范产生差距,如果要分析程序如果执行,最常见的就是通过软件调试工具(GDB、Windbg 等)断点调试,但是对于 Java 来说,很多执行代码是通过 JIT 动态生成到 CodeBuffer 中的;
功能:HSDIS 是官方推荐的 HotSpot 虚拟机 JIT 编译代码的反汇编工具,它包含在 HotSpot 虚拟机的源码中但没有提供编译后的程序,可以自己下载放到 JDK 的相关目录里;
4.3 JDK 的可视化工具
JConsole:Java 监视与管理控制台
是一种基于 JMX 的可视化监控和管理工具,它管理部分的功能是针对 MBean 进行管理,由于 MBean 可以使用代码、中间件服务器或者所有符合 JMX 规范的软件进行访问,因此这里着重介绍 JConsole 的监控功能;
通过 jconsole 命令启动 JConsole 后,会自动搜索本机所有虚拟机进程。另外还支持远程进程的监控;
进入主界面,支持查看以下标签页:概述、内存、线程、类、VM 摘要和 MBean;
VisualVM:多合一故障处理工具
目前为止 JDK 发布的功能最强调的运行监控和故障处理程序,另外还支持性能分析;
VisualVM 还有一个很大的优点:不需要被监视的程序基于特殊 Agent 运行,对应用程序的实际性能影响很小,可直接应用在生成环境中;
VisualVM 基于 NetBeans 平台开发,具备插件扩展功能的特性,基于插件可以做到:显示虚拟机进程以及进程配置、环境信息(jps、jinfo)、监视应用程序的 CPU、GC、堆、方法区以及线程的信息(jstat、jstack)、dump 以及分析堆转储快照(jmap、jhat)、方法级的程序运行性能分析,找出被调用最多运行时间最长的方法、离线程序快照(收集运行时配置、线程 dump、内存 dump 等信息建立快照)、其他 plugins 的无限可能。
使用 jvisualvm 首次启动时需要在线自动安装插件(也可手工安装);
特色功能:生成浏览堆转储快照(摘要、类、实例标签页、OQL 控制台)、分析程序性能(Profiler 页签可以录制一段时间程序每个方法执行次数和耗时)、BTrace 动态日志跟踪(不停止目标程序运行的前提下通过 HotSwap 技术动态加入调试代码);
4.4 本章小结
本章介绍了随 JDK 发布的 6 个命令行工具以及两个可视化的故障处理工具,灵活运行这些工具可以给问题处理带来很多便利。我的总体感觉是可视化工具虽然强大,但是加载速度相比命令行工具慢很多,这个时候专注于某个功能的命令行工具是更优的选择。
第 5 章 调优案例分析与实战
5.1 概述
除了第四章介绍的知识和工具外,在处理实际问题时,经验同样很重要。
5.2 案例分析
5.3 实战:Eclipse 运行速度调优
升级 JDK;
设置 -XX:MaxPermSize=256M 解决 Eclipse 判断虚拟机版本的 bug;
加入参数 -Xverfify:none 禁止字节码验证;
虚拟机运行在 client 模式,采用 C1 轻量级编译器;
把 -Xms 和 -XX:PermSize 参数设置为 -Xmx 和 -XX:MaxPermSize 一样,这样强制虚拟机启动时把老年代和永久代的容量固定下来,避免运行时自动扩展;
增加参数 -XX:DisableExplicitGC 屏蔽掉显式 GC 触发;
采用 ParNew+CMS 的垃圾收集器组合;
最终从 Eclipse 启动耗时 15 秒到 7 秒左右, eclipse.ini 配置如下:
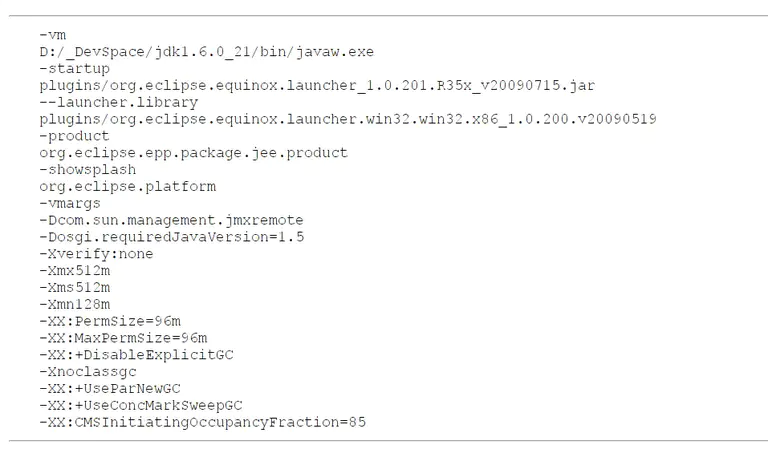
5.4 本章小结
Java 虚拟机的内存管理和垃圾收集是虚拟机结构体系最重要的组成部分,对程序的性能和稳定性有非常大的影响。通过案例和实战部分,加深了对前面理论知识和工具的理解。
第三部分 虚拟机执行子系统
第 6 章 类文件结构
6.1 概述
由于虚拟机以及建立在虚拟机之上的编程语言蓬勃发展,将程序编译成二进制本地机器码已不再是唯一选择,越来越多的程序语言选择了与操作系统和机器指令集无关的、平台中立的格式作为程序编译后的存储格式。
6.2 无关性的基石
各种不同平台的虚拟机与所有平台都统一使用的程序存储格式——字节码(ByteCode)是构成平台无关性的基石;实现语言无关性的基础仍然是虚拟机和字节码存储格式。
6.3 Class 类文件结构
任何一个 Class 文件都对应着唯一一个类或接口的定义信息,但反过来说,类或接口并不一定都得定义在文件里(譬如类或接口也可以通过类加载器直接生成)。
Class 文件是一组 8 位字节为基础的二进制流,各个数据项目严格按照顺序紧凑地排列在 Class 文件之中,中间没有添加任何分隔符。当遇到需要占用 8 位字节以上空间的数据项目时,则会按照高位在前的方式分割成若干个 8 为字节来存储。
根据 Java 虚拟机规定,Class 文件格式采用一种类似 C 语言结构体的伪结构来存储数据,这种伪结构只有两种数据类型:无符号数和表。
无符号数属于基本的数据类型,以 u1、u2、u4、u8 来分别代表 1 个字节、2 个字节、4 个字节和 8 个字节的无符号数、无符号数可以用来描述数字、索引引用、数量值或者按照 UTF-8 编码构成字符串值。
表是由多个无符号数或者其他表作为数据项构成的复合数据类型,所有表都以“_info”结尾。表用于描述有层次关系的复合结构的数据,整个 Class 文件本质上就是一张表。

6.3.1 魔数和版本
每个 Class 文件的头 4 个字节称为魔数,它的唯一作用是确定这个文件是否为一个能被虚拟机接受的 Class 文件。
紧接着魔数存储的 4 个字节存储的是 Class 文件的版本号:5、6 字节是次版本号,7、8 字节是主版本号。
6.3.2 常量池
常量池可以理解为 Class 文件之中的资源仓库,由于常量池中的常量数量不固定,因此需要在常量池前放置一项 u2 类型的数据来表示容量,该值是从 1 开始的,上图的 0x0013 为十进制的 19,代表常量池中有 18 项常量,索引值范围为 1~18;常量池主要存放两大类常量:字面量(比如文本字符串和 final 常量等)和符号引用(包括类和接口的全限定名、字段的名称和描述符、方法的名称和描述符);
6.3.3 访问标志
紧接在常量池后面的是两个字节的访问标志,用于标识类或接口的访问信息。
6.3.4 类索引、父类索引与接口索引集合
类索引:u2 类型的数据,用于确定类的全限定名。
父类索引:u2 类型的数据,用于确定父类的全限定名。
接口索引计算器:u2 类型的数据,用于表示索引集合的容量。
接口索引集合:一组 u2 类型的数据的集合,用于确定实现的接口(对于接口来说就是 extend 的接口)。
6.3.5 字段表集合
用于描述接口或者类中声明的变量,包括类级变量和实例级变量,但不包括方法内部声明的局部变量;它不会列出从父类和超类继承而来的字段;
6.4 字节码指令简介
Java 虚拟机的指令由一个字节长度的、代表着特定操作含义的数字(操作码)以及跟随其后的零至多个代表此操作所需参数(称为操作数)而构成。由于 Java 虚拟机采用面向操作数栈而不是寄存器的架构,所以大多数的指令都不包含操作数,只有一个操作码。
** 加载和存储指令 **:iload/iload_ 等(加载局部变量到操作栈)、istore/istore_ 等(从操作数栈存储到局部变量表)、bipush/sipush/ldc/iconst(加载常量到操作数栈)、wide(扩充局部变量表访问索引);
运算指令:没有直接支持 byte、short、char 和 boolean 类型的算术指令而采用 int 代替;iadd/isub/imul/idiv 加减乘除、irem 求余、ineg 取反、ishl/ishr 位移、ior 按位或、iand 按位与、ixor 按位异或、iinc 局部变量自增、dcmpg/dcmpl 比较;
类型转换指令:i2b/i2c/i2s/l2i/f2i/f2l/d2i/d2l/d2f;
对象创建与访问指令:new 创建类实例、newarray/anewarray/multianewarray 创建数组、getfield/putfield/getstatic/putstatic 访问类字段或实例字段、baload/iaload/aaload 把一个数组元素加载到操作数栈、bastore/iastore/aastore 将一个操作数栈的值存储到数组元素中、arraylength 取数组长度、instanceof/checkcast 检查类实例类型;
操作数栈管理指令:pop/pop2 一个或两个元素出栈、dup/dup2 复制栈顶一个或两个数组并将复制值或双份复制值重新压力栈顶、swap 交互栈顶两个数值;
控制转移指令:ifeq/iflt/ifnull 条件分支、tableswitch/lookupswitch 复合条件分支、goto/jsr/ret 无条件分支;
方法调用和返回指令:invokevirtual/invokeinterface/invokespecial/invokestatic/invokedynamic 方法调用、ireturn/lreturn/areturn/return 方法返回;
异常处理指令:athrow
同步指令:monitorenter/monitorexit
6.5 公有设计和私有实现
Java 虚拟机的实现必须能够读取 Class 文件并精确实现包含在其中的 Java 虚拟机代码的含义;
但一个优秀的虚拟机实现,通常会在满足虚拟机规范的约束下具体实现做出修改和优化;
虚拟机实现的方式主要有两种:将输入的 Java 虚拟机代码在加载或执行时翻译成另外一种虚拟机的指令集或宿主主机 CPU 的本地指令集。
6.6 Class 文件结构的发展
Class 文件结构一直比较稳定,主要的改进集中向访问标志、属性表这些可扩展的数据结构中添加内容;
Class 文件格式所具备的平台中立、紧凑、稳定和可扩展的特点,是 Java 技术体系实现平台无关、语言无关两项特性的重要支柱;
6.7 本章小结
第 7 章 虚拟机类加载机制
7.1 概述
虚拟机把描述类的数据从 Class 文件加载到虚拟机,并对数据进行校验、转换解析和初始化,最终形成可以被虚拟机直接使用的 java 类型,这就是虚拟机的类加载机制。在 Java 语言里面,类的加载和连接过程都在程序运行期间完成的。
7.2 类加载时机
类从加载到虚拟机内存中开始,到卸载出内存为止,它的整个生命周期包括了:加载(Loading)、验证(Verification)、准备(Preparation)、解析(Resolution)、初始化(Initialization)、使用(Using)和卸载(Unloading)7 个阶段。其中,验证、准备、解析 3 个部分成为连接(Linking)。
加载:java 虚拟机规范没有强制规定加载时机,具体由虚拟机具体实现自有把握。
初始化:虚拟机规范严格控制规定了有且只有四种情况必须立即对类进行“初始化”(而加载、验证、准备自然需要在这些之前开始)。
(1)使用 new 关键字实例化对象、读取或设置一个类的静态字段(被 final 修饰、已在编译期把结果放入常量池的静态字段除外)、以及调用一个类的静态方法的时候。
(2)使用 java.lang.reflect 包的方法对类进行反射调用的时候,如果类没有进行过初始化,则需要先触发其初始化;
(3)当初始化一个类的时候,如果发现其父类还没有进行过初始化,则需要先触发其父类的初始化;
(4)当虚拟机启动时,用户需要指定一个要执行的主类(包括 main 方法的那个类),虚拟机会先初始化这个主类。注意,接口的情况并不适合第三种情况。即一个接口在初始化时,并不要求其父接口全部都完成初始化了,只有在真正使用到父接口的时候(如引用接口中定义的常量)才会初始化。
(5)使用 1.7 的动态语言支持。如果个 java.lang.invoke.MethodHandle 解析结果为 REF_getStatic、REF_putStatic、REF_invokeStatic 的方法句柄,并且该类对应的类没有初始化,触发该类的初始化
7.3 类加载的过程
加载、连接(验证、准备、解析)、初始化的解析。
1、加载
加载时类加载过程的一个阶段,虚拟机需要完成三件事情:
1)通过一个类的权限定名来获取定义此类的二进制字节流。
2)将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。
3)在 Java 堆中生成一个代表这个类的 java.lang.Class 对象,作为方法区这些数据的访问入口,对于数组,不是由类加载器创建,而是由 Java 虚拟机直接创建。
2、验证
验证是连接阶段的第一步,来确保包含的信息是否符合当前虚拟机的要求和是否会危害虚拟机自身的安全。大致分为四个检验过程:文件格式验证、元数据验证、字节码验证和符号引用验证。
文件格式验证:主要是文件格式规范和版本验证。
元数据验证:主要是对字节码描述的信息进行 语义分析,以确保其描述的信息符合 Java 语言规范的要求。
字节码验证:主要是数据流和控制流分析,任务是保证被校验类的方法在运行时不会做出危害虚拟机安全的行为。
符号引用验证:发生在虚拟机将符号引用转换为直接引用的时候,可以看做是对类自身以外(常量池中的各种符号引用)的信息进行匹配性校验。目标是确保解析动作能正常执行。
3、准备
准备阶段正式为类变量分配内存并设置类变量初始化阶段,这些内存将在方法区中进行分配。进行内存分配的仅包括类变量(被 static 修饰的变量),而不是实例常量,实例常量将会在对象实例化时随着对象一起分配到 Java 堆中。
4、解析
解析阶段是虚拟机将常量池内的符号引用替换为直接引用的过程。解析动作主要针对类或接口、字段、类方法、接口方法四类符号引用进行。
5、初始化
类初始化阶段是类加载过程的最后一步。在准备阶段,类变量已经赋过一次系统要求的初始值,而在初始化阶段,则是根绝程序员通过程序制定的主观计划去初始化类变量和其他资源,或者从另外一个角度来表达:初始化阶段是执行类构造器方法的过程。
7.4 类加载器
1、类和类加载器
类加载器虽然只用于实现类的加载动作,但他在 Java 程序中起到的作用远远不限于类加载阶段。对于任意一个类,都需要由加载他的类加载器和类本身来确立在 Java 虚拟机中的唯一性。
2、双亲委派模式
从 Java 虚拟机的角度讲,只存在两种不同的类加载器:一种是启动类加载器(Bootstrap ClassLoader),这个类加载器使用 C++ 语言实现,是虚拟机自身的一部分;另外一种就是所有的其他类加载器,这些类加载器都是由 java 语言实现,独立于虚拟机外部,并且全部继承自抽象类 java.lang.ClassLoader。
从 Java 程序员的角度看,绝大部分 Java 程序都会使用到以下三种系统提供的类加载器:
启动类加载器(Bootstrap ClassLoader):负责将 \lib 目录中的,或者被 -Xbootclasspath 参数所指定的路径中的,并且是虚拟机识别的类库加载到虚拟机内存中。启动类加载器无法被 Java 程序直接应用。
扩展类加载器(Extension ClassLoader):这个加载器有 sun.misc.Launcher$ExtClassLoader 实现,他负责加载 \lib\ext 目录中的,或者被 java.ext.dirs 系统变量所指定的路径中的所有类库,开发者可以直接使用扩展类加载器。
应用程序类加载器 (Application ClassLoader):这个类加载器有 sun.misc.Launcher$AppClassLoader 实现。负责加载用户类路径(ClassPath)上所指定的类库。
** 双亲委派模式(Parents Delegation Model)**:要求除了顶层的类加载器外,其余的类加载器都应有自己的父类加载器。一般这种父子关系不是继承关系,而是组合关系来复用父加载器的代码。
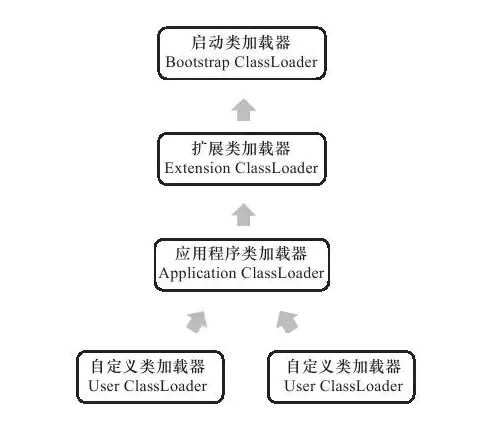
** 双亲委派模式的工作过程是 **:如果一个类加载器收到了类加载的请求,他首先不会自己去尝试加载这个类,而且把这个请求委派给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的请求最终都应该传送到顶层的启动类的加载器中,只要当父类返回无法完成这个加载请求时(就是查找范围没有查找到这个类),子加载器才会尝试去加载。
使用双亲委派模型来组织加载器之间的关系,一个明显的好处是:Java 类随它的类加载器一起具备了一种带优先级的层次关系。
3、破坏双亲委派模式
1)第一次被破坏是在双亲委派模型出现之前(JDK1.2 发布之前),JDK1.2 之后不在提倡重写 loadClass() 方法,而是使用 findClass 方法。
2) 第二次被破坏是由于该模型自身的缺陷造成的,如 JNDI、JDBC 等
3)第三次被破坏由于对动态性追求造成的,例如: OSGi 而是网状结构的加载模式。
第 8 章 虚拟机字节码执行引擎
8.1 概述
所有的 Java 虚拟机的执行引擎:输入的是字节码文件,处理过程是字节码解析的等效过程,输出的是执行结果。
8.2 运行时栈帧结构
栈帧是虚拟机用于方法调用和方法执行的数据结构,是虚拟机运行时数据区的虚拟机栈的栈元素。栈帧存储了方法的局部变量表、操作数栈、动态连接、方法返回地址等信息。每一个方法从调用开始到执行结束,就是栈帧在虚拟机栈中入栈出栈的过程。在编译期间,栈帧需要多大的局部变量表、多深的操作数栈都已经完全确定,并且写入方法的 code 属性中。一个栈帧需要分配多大内存,不会受到程序运行期变量数据影响。在活动线程中,栈顶的栈帧才是有效的,称为当前栈帧,相关联的方法称为当前方法。
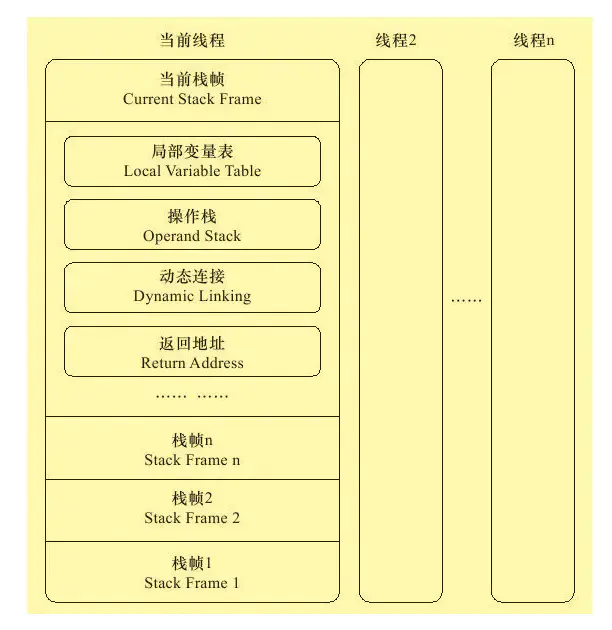
8.2.1 局部变量表
是一组变量值存储空间,用于存放方法参数和方法内部定义的局部变量
8.2.2 操作数栈(操作栈)
是一个后入先出栈,在编译时候写入 code 属性的 max_stacks 数据项中。
8.2.3 动态连接
每个栈帧都有一个指向运行时常量池中该栈帧所属方法的引用,持有这个引用是为了支持方法调用过程中的动态连接
8.2.4 方法返回地址
正常完成出口:PC 计数器的值可以作为返回地址,栈帧中很可能保存这个计数值
异常完成出口:通过异常处理器表来确定返回地址,栈帧中一般不会保存这部分信息
方法退出等同于当前栈帧出栈,可能执行的操作有:恢复上层方法的局部变量表和操作数栈,把返回值(如果有的话)压入调用者栈帧的操作数栈中,调整 PC 计数器的值以指向方法调用指令后面的一条指令
8.2.5 附加信息
8.3 方法调用
方法调用不等同于方法执行,唯一任务就是确定被调用方法的版本,暂不涉及方法内部的具体运行过程。一切方法调用在 Class 文件里面存储的都只是符号引用,而不是内存布局中的入口地址。
8.3.1 解析
调用目标在程序写好、编译器进行编译时就必须确定下来,这类方法的调用称为解析
Java 中符合“编译期可知,运行期不变”要求的方法主要包括:静态方法,私有方法两大类。与之相对应的 5 条方法调用字节码指令
invokestatic:调用静态方法
invokespecial:调用实例构造器 init 方法、私有方法、父类方法
invokevirtual:调用所有的虚方法
invokeinterface:调用接口方法,会在运行时再确定一个实现此接口的对象
invokedynamic:现在运行时动态解析出调用点限定符所引用的方法,然后再执行该方法
只要能被 invokestatic 和 invokespecial 指令调用的方法,都可以再解析阶段中确定唯一的调用版本,符合这个条件的由静态方法、构造方法、私有方法、父类方法四大类,这些方法称为非虚方法(还包含 final 修饰的方法,无法被覆盖,没有其他版本);与之相反的称为虚方法(final 修饰除外)
8.3.2 分派
解析调用是一个静态过程,而分派调用可能是静态调用,也可能是动态调用。分派调用过程将揭示多态特征的一些最基本的体现。
1、静态分派
所有依赖静态类型来定位方法执行版本的分派称为 ** 静态分派。** 静态分派的典型应用就是方法重载,动态分派是重写。静态分派发生在编译阶段。
2、动态分派
运行期根据实际类型确定方法版本的分派称为动态分派。 动态分派典型应用就是重写。
3、单分派和多分派
方法的接受者方法的参数统称为方法的宗量,根据分派基于多少种宗量,可以将分派划分为单分派和多分派。单分派是根据一个宗量对目标方法进行选择,多分派是根据多于一个宗量对目标方法进行选择。静态分派属于多分派,动态分派属于单分派。
4、虚拟机动态分派的实现
在方法区中建立一个虚方法表(Virtual Method Table),使用虚方法表索引来代替元数据查找以提高性能;方法表一般在类加载的连接阶段进行初始化,准备了类的变量初始化值后,虚拟机会把该类的方法表也初始化完毕;
8.3.3 动态类型语言支持
JDK 1.7 发布增加的 invokedynamic 指令实现了“动态类型语言”支持,也是为 JDK 1.8 顺利实现 Lambda 表达式做技术准备。动态类型语言的关键特征是它的类型检查的主体过程是在运行期而不是编译器。Java 语言在编译期间就将方法完整的符号引用生成出来,作为方法调用指令的参数存储到 Class 文件中;这个符号引用包含了此方法定义在哪个具体类型之中、方法的名字以及参数顺序、参数类型和方法返回值等信息。
JDK 1.7 实现了 JSR-292,新加入的 java.lang.invoke 包的主要目的是在之前单纯依靠符号引用来确定调用的目标方法外,提供一种新的动态确定目标方法的机制,称为 MethodHandle;
从本质上讲,Reflection(反射)和 MethodHandle 机制都是在模拟方法调用,但 Reflection 是在模拟 Java 代码层次的方法调用,而 MethodHandle 是在模拟字节码层次的方法调用,前者是重量级,而后者是轻量级;另外前者只为 Java 语言服务,后者可服务于所有 Java 虚拟机之上的语言;
每一处含有 invokedynamic 指令的位置都称为“动态调用点 (Dynamic Call Site)”,这条指令的第一个参数不再是代表符号引用的 CONSTANT_Methodref_info 常量,而是 CONSTANT_InvokeDynamic_info 常量(可以得到引导方法、方法类型和名称);
invokedynamic 指令与其他 invoke 指令的最大差别就是它的分派逻辑不是由虚拟机决定的,而是由程序员决定的;
8.4 基于栈的字节码解释执行引擎
上节主要讲虚拟机是如何调用方法的,这节探讨虚拟机是如何执行方法中的字节码指令的。
8.4.1 解释执行
javac 编译器完成了程序代码经过词法分析、语法分析到抽象语法树,在遍历语法树生成线性的字节码指令流的过程,一部分在虚拟机之外进行,而解释器是在虚拟机内部,所以 Java 程序的编译是半独立的实现。
8.4.2 基于栈的指令集和基于寄存器的指令集
Java 编译器输出的指令集,基本上是一种基于栈的指令集架构,指令流中的指令大部分是零地址指令,它们依赖操作数栈进行工作;
基于栈的指令集主要的优点是可移植性,寄存器由硬件直接提供,程序直接依赖这些硬件寄存器则不可避免地要受到硬件的约束;主要缺点是执行速度相对来说会稍慢一点;
8.4.3 基于栈的解释器执行过程
第 9 章 类加载及执行子系统的案例与实战
9.1 概述
在 Class 文件格式与执行引擎这部分中,用户的程序能直接影响的内容并不多;能通过程序进行操作的,主要是字节码生成与类加载器这两部分的功能,但仅仅在如何处理这两点上,就已经出现了许多值得欣赏和借鉴的思路;
9.2 案例分析
9.2.1 Tomcat:正统的类加载器架构
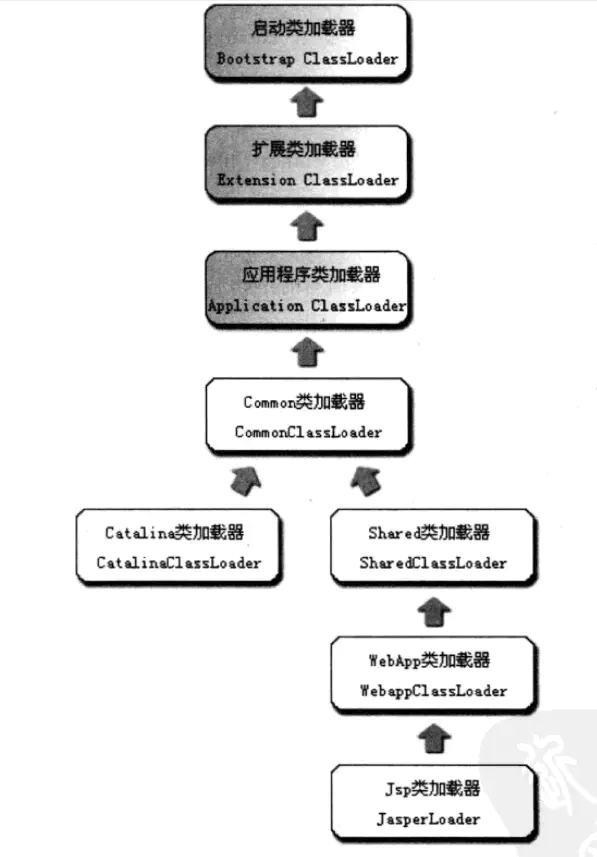
Tomcat 服务器的类加载架构
Java Web 服务器:部署在同一个服务器上的两个 Web 应用程序所使用的 Java 类库可以实现相互隔离又要可以互相共享;尽可能保证自身的安全不受部署的 Web 应用程序影响;要支持 JSP 生成类的热替换;
上图中,灰色背景的三个类加载器是 JDK 默认提供的类加载器,而 CommonClassLoader、CatalinaClassLoader、SharedClassLoader 和 WebappClassLoader 是 Tomcat 自己定义的类加载器,分别加载 /common/(可被 Tomcat 和 Web 应用共用)、/server/(可被 Tomcat 使用)、/shared/(可被 Web 应用使用)和 /WebApp/WEB-INF/(可被当前 Web 应用使用)中的 Java 类库,Tomcat 6.x 把前面三个目录默认合并到一起变成一个 /lib 目录(作用同原先的 common 目录);
9.2.2 OSGI:灵活的类加载架构
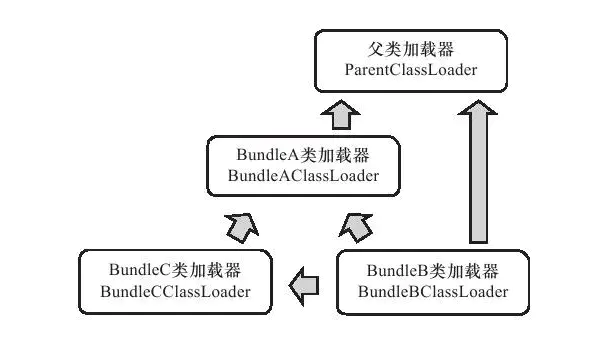
OSGI 的每个模块称为 Bundle,可以声明它所依赖的 Java Package(通过 Import-Package 描述),也可以声明它允许导出发布的 Java Package(通过 Export-Package 描述);除了更精确的模块划分和可见性控制外,引入 OSGI 的另外一个重要理由是基于 OSGI 的程序很可能可以实现模块级的热插拔功能;OSGI 的类加载器之间只有规则,没有固定的委派关系;加载器之间的关系更为复杂、运行时才能确定的网状结构,提供灵活性的同时,可能会产生许多的隐患;
9.2.3 字节码生成技术与动态代理的实现
在 Java 里面除了 javac 和字节码类库外,使用字节码生成的例子还有 Web 服务器中的 JSP 编译器、编译时植入的 AOP 框架和很常用的动态代理技术等,这里选择其中相对简单的动态代理来看看字节码生成技术是如何影响程序运作的;动态代理的优势在于实现了在原始类和接口还未知的时候就确定类的代理行为,可以很灵活地重用于不同的应用场景之中;以下的例子中生成的代理类“$Proxy0.class”文件可以看到代理为传入接口的每一个方法统一调用了 InvocationHandler 对象的 invoke 方法;其生成代理类的字节码大致过程其实就是根据 Class 文件的格式规范去拼接字节码;
9.2.4 Retrotranslator:跨越 JDK 版本
Retrotranslator 的作用是将 JDK 1.5 编译出来的 Class 文件转变为可以在 JDK 1.4 或 JDK 1.3 部署的版本,它可以很好地支持自动装箱、泛型、动态注解、枚举、变长参数、遍历循环、静态导入这些语法特性,甚至还可以支持 JDK 1.5 中新增的集合改进、并发包以及对泛型、注解等的反射操作;JDK 升级通常包括四种类型:编译器层面的做的改进、Java API 的代码增强、需要再字节码中进行支持的活动以及虚拟机内部的改进,Retrotranslator 只能模拟前两类,第二类通过独立类库实现,第一类则通过 ASM 框架直接对字节码进行处理;
9.3 实战:自己动手实现远程执行功能
第四部分 程序编译与代码优化
第 10 章 早期(编译期)优化
10.1 概述
前端编译器(或叫编译器前端):把 _.java 文件转变为 _.class 文件的过程,比如 Sun 的 javac、Eclipse JDT 中的 ECJ;
后端运行编译器(JIT 编译器):把字节码转变为机器码的过程,比如 HotSpot VM 的 C1、C2 编译器;
静态提前编译器(AOT 编译器):直接把 *.java 文件编译成本地机器代码的过程,比如 GNU Compiler for the Java;
本章主要针对第一类,把第二类的编译过程留到下一章讨论;
javac 这类编译器对代码运行效率几乎没有任何优化措施,虚拟机设计团队把对性能的优化集中到了后端的即时编译器中,这样那些不是由 javac 产生的 Class 文件也同样能享受到编译器优化所带来的好处;
javac 做了许多针对 Java 语言编码过程的优化措施来改善程序员的编码风格和提高编码效率;可以说,Java 中即时编译器在运行期的优化过程对于程序运行来说更重要,而前端编译器在编译器的优化过程对于程序编码来说关系更加密切;
10.2 javac 编译器
javac 编译器本身就是一个由 Java 语言编写的程序,这为纯 Java 的程序员了解它的编译过程带来了很大的便利。
10.2.1 javac 的源码与调试
javac 的源码存放在 JDK_SRC_HOME/langtools/src/share/classes/com/sun/tools/javac,除了 JDK 自身的 API 外,就只引用了 JDK_SRC_HOME/langtools/src/share/classes/com/sun/* 里面的代码;
导入 javac 的源码后就可以运行 com.sun.tools.javac.Main 的 main 方法来执行编译了;
javac 编译过程大概可以分为 3 个过程:解析与填充符号表过程、插入式注解处理器的注解处理过程、分析与字节码生成过程;

10.2.2 解析与填充符号表
解析步骤由 parseFiles 方法完成;
词法分析将源代码的字符流转变为标记(Token)集合,由 com.sun.tools.javac.parser.Scanner 类完成;
语法分析是根据 Token 序列构造抽象语法树(AST,一种用来描述程序代码语法结构的树形表示方式)的过程,由 com.sun.tools.javac.parser.Parser 类实现,AST 由 com.sun.tools.javac.tree.JCTree 类表示;
填充符号表:由 enterTrees 方法完成;符号表是由一组符号地址和符号信息构成的表格,所登记的信息在编译的不同阶段都要用到,在语义分析中用于语义检查,在目标代码生成时用于地址分配;由 com.sun.tools.javac.comp.Enter 类实现;
10.2.3 注解处理器
在 JDK 1.6 中实现了 JSR-269 规范,提供了一组插入式注解处理器的标准 API 在编译期间对注解进行处理,可以读取、修改、添加抽象语法树中的任意元素;
通过插入式注解处理器实现的插件在功能上有很大的发挥空间,程序员可以使用插入式注解处理器来实现许多原本只能在编码中完成的事情;
javac 中,在 initProcessAnnotations 初始化,在 processAnnotations 执行,如果有新的注解处理器,通过 com.sun.tools.javac.processing.JavacProcessingEnviroment 类的 doProcessing 方法生成一个新的 JavaCompiler 对象对编译的后续步骤进行处理;
10.2.4 语义分析与字节码生成
语义分析的主要任务是对结构上正确的源程序进行上下文有关性质的审查,主要包括标注检查、数据及控制流分析两个步骤;
** 解语法糖 **(Syntactic Sugar,添加的某种对语言功能没有影响但方便程序员使用的语法):Java 中最常用的语法糖主要是泛型、变长参数、自动装箱等,他们在编译阶段还原回简单的基础语法结构;在 com.sun.tools.javac.comp.TransTypes 类和 com.sun.tools.javac.comp.Lower 类中完成;
字节码生成:javac 编译的最后一个阶段,不仅仅是把前面各个步骤所生成的信息转化为字节码写入到磁盘中,编译器还进行了少量的代码添加和转换工作(如实例构造器方法和类构造器方法);由 com.sun.tools.javac.jvm.ClassWriter 类的 writeClass 方法输出字节码,生成最终的 Class 文件;
10.3 Java 语法糖的味道
10.3.1 泛型与类型擦除
Java 语言的泛型只在程序源码中存在,在编译后的字节码文件中,就已经替换为原来的原生类型了,并且在相应的地方插入了强制转换,这种基于类型擦除的泛型实现是一种伪泛型;
JCP 组织引入了 Signature 属性,它的作用就是存储一个方法在字节码层面的特征签名,这个属性中保存的参数类型并不是原生类型,而是包括了参数化类型的信息,这样我们就可以通过反射手段获取参数化类型;
10.3.2 自动装箱、拆箱与遍历循环
它们的实现比较简单,但却是 Java 语言里使用最多的语法糖;
10.3.3 条件编译
Java 语言之中并没有使用预处理器,因为 Java 编译器并非一个个地编译 Java 文件,而是将所有编译单元的语法树顶级节点输入到待处理列表后再进行编译;
Java 语言可以使用条件为常量的 if 语句进行条件编译;编译器将会把分支中不成立的代码块消除掉;
10.4 实战:插入式注解处理器
第十一章 晚期(运行期)优化
11.1 概述
为了提高热点代码的执行效率,在运行时虚拟机将会把这些代码编译成与本地平台相关的机器码,并进行各种层次的优化,完成这个任务的编译器称为即时编译器(JIT);JIT 不是虚拟机必需的,但是其编译性能的好坏、代码优化程度的高低却是衡量一款商用虚拟机优秀与否的最关键的指标之一,它也是虚拟机中最核心且最能体现虚拟机技术水平的部分;
11.2 HotSpot 虚拟机内的即时编译器
11.2.1 解释器与编译器
当程序需要迅速启动和执行的时候,解释器可以先发挥作用,省去编译的时间立即执行;在程序运行后,随着时间的推移,编译器把越来越多的代码编译成本地代码提升执行效率;
HotSpot 虚拟机中内置了两个即时编译器,分别为 Client Compiler 和 Server Compiler,或简称为 C1 编译器和 C2 编译器;虚拟机会根据自身版本与宿主机器的硬件性能自动选择运行模式,也可以使用“-client”或“-server”参数去强制指定运行模式;
想要编译出优化程度更高的代码,解释器可能还要替编译器收集性能监控信息,为了在程序启动响应速度与运行效率之间达到最佳平衡,HotSpot 虚拟机还会逐渐启动分层编译的策略:第 0 层,程序解释运行;第 1 层,C1 编译;第 2 层,C2 编译;
实施分层编译后,Client Compiler 和 Server Compiler 将会同时工作,许多代码都可能会被多次编译,用 Client Compiler 获取更高的编译速度,用 Server Compiler 来获取更好的编译质量,在解释执行的时候也无须再承担性能收集监控信息的任务;
11.2.2 编译对象与触发条件
被 JIT 编译的热点代码有两类:被多次调用的方法、被多次执行的循环体;对于前者编译器会以整个方法作为编译对象,属于标准的 JIT 编译方式;对于后者尽管编译动作是由循环体所触发的,但编译器依然会以整个方法作为编译对象,这种编译方式称之为栈上替换(OSR 编译);
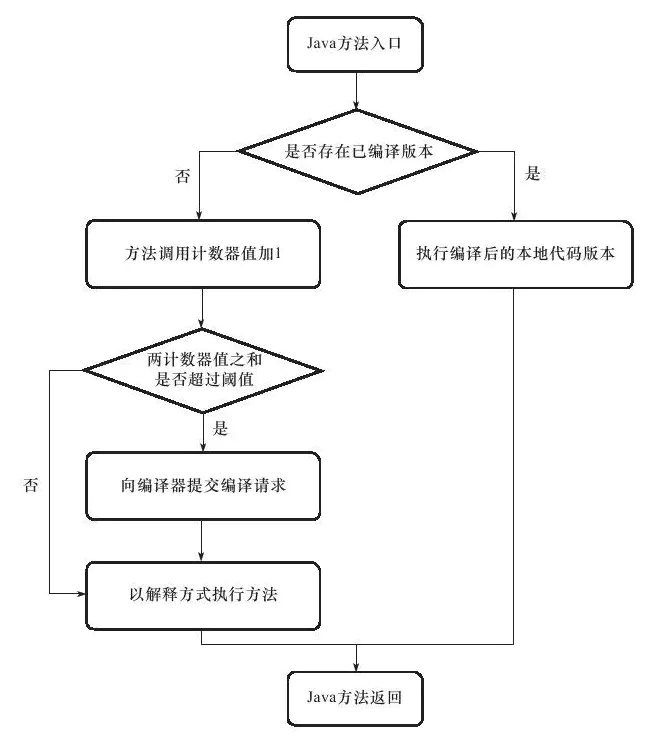
热点探测:基于采样的热点探测和基于计数器的热点探测,在 HotSpot 虚拟机中使用的是第二种,通过方法计数器和回边计数器进行热点探测。方法调用计数器触发的即时编译交互过程如下图所示:
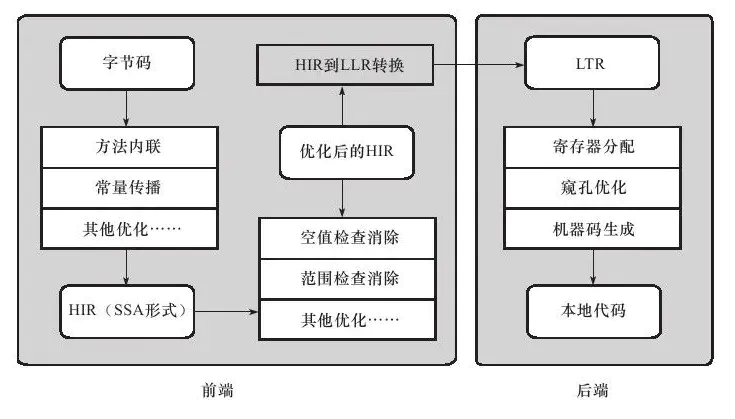
对于 Client Compiler 来说,它是一个简单快速的三段式编译器,主要的关注点在于局部性的优化,而放弃了很多耗时较长的全局优化手段;第一阶段一个平台独立的前端将字节码构造成一个高级中间代码表示(HIR),第二阶段一个平台相关的后端从 HIR 中产生低级中间代码表示(LIR),最后阶段是在平台相关的后端使用线性扫描算法在 LIR 上分配寄存器,并在 LIR 上做窥孔优化,然后产生机器代码。其大致过程如下所示:
Server Compiler 是专门面向服务端的典型应用并为服务端的性能配置特别调整过的编译器,也是一个充分优化过的高级编译器,几乎能达到 GNU C++ 编译器使用 -02 参数时的优化强大,它会执行所有经典的优化动作,如无用代码消除、循环展开、循环表达式外提、消除公共子表达式、常量传播、基本块重排序等,还会实现如范围检查消除、空值检查消除等 Java 语言特性密切相关的优化技术;
11.2.4 查看及分析即时编译结果
本节的运行参数有一部分需要 Debug 或 FastDebug 版虚拟机的支持;
要知道某个方法是否被编译过,可以使用参数 -XX:+PrintCompilation 要求虚拟机在即时编译时将被编译成本地代码的方法名称打印出来;
还可以加上参数 -XX:+PrintInlining 要求虚拟机输出方法内联信息,输出内容如下:

除了查看那些方法被编译之外,还可以进一步查看即时编译器生成的机器码内容,这个需要结合虚拟机提供的反汇编接口来阅读;
11.3 编译优化技术
11.3.1 优化技术概览
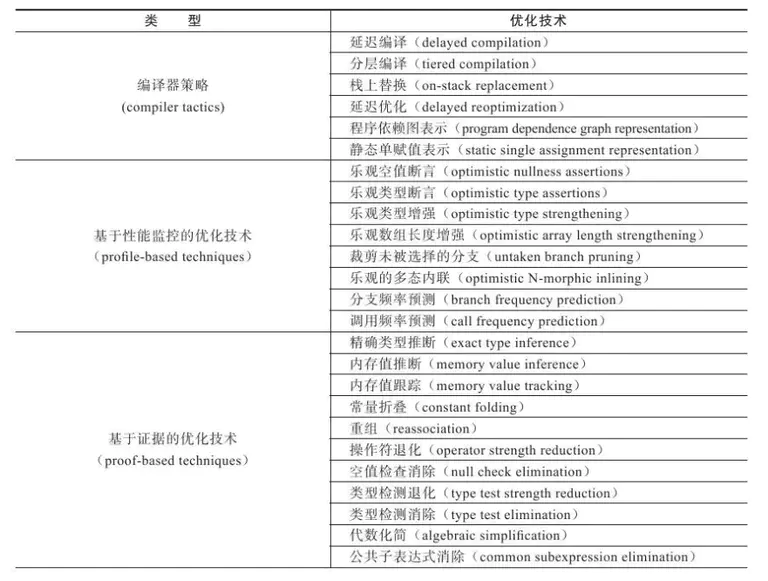

11.3.2 公共子表达式消除
如果一个表达式 E 已经计算过了,并且从先前的计算到现在 E 中所有变量的值都没有发生变化,那么 E 的这次出现就成为了公共子表达式,只需要直接用前面计算过的表达式结果代替 E 就可以了;
11.3.3 数组边界检查消除
对于虚拟机的执行子系统来说,每次数组元素的读写都带有一次隐含的条件判断,对于拥有大量数组访问的程序代码无疑是一种性能负担;
11.3.4 方法内联
除了消除方法调用的成本外更重要的意义是为其他优化手段建立良好的基础;
为了解决虚方法的内联问题,引入了类型继承关系分析(CHA)技术和内联缓存(Inline Cache)来完成方法内联;
11.3.5 逃逸分析
逃逸分析的基本行为就是分析对象动态作用域,当一个对象在方法中被定义后,它可能被外部方法所引用(方法逃逸),甚至还可能被外部线程所访问到(线程逃逸);如果能证明一个对象不会逃逸到方法或线程之外,则可能为这个变量进行一些高效的优化,比如栈上分配(减轻垃圾收集的压力)、同步消除(读写不会有竞争)、标量替换;
11.4 Java 与 C/C++ 的编译器对比
Java 虚拟机的即时编译器与 C/C++ 的静态优化编译器相比,可能会由于下列这些原因而导致输出的本地代码有一些劣势:即时编译器运行占用用户程序运行时间、动态类型安全语言导致的频繁检查、运行时对方法接收者进行多态选择的频率大、可以动态扩展导致很多全局的优化难以运行、大部分对象在堆上分配导致垃圾收集机制的效率低;
Java 语言的特性换取了开发效率的提升、还有许多优化是静态优化编译器不好做的,比如别名分析、还有一些以运行期性能监控为基础的优化措施如调用频率预测等;
11.5 本章小结
本章我们着重了解了虚拟机的热点探测方法、HotSpot 的即时编译器、编译触发条件以及如何从虚拟机外部观察和分析 JIT 编译的数据和结果,还选择了集中场景的编译期优化技术进行讲解。对 Java 编译器的深入了解,有助于在工作中分辨哪些代码是编译器可以帮我们处理的,哪些代码需要自己调节以便更适合编译器的优化。
第五部分 高效并发
第 12 章 Java 内存模型与线程
并发处理的广泛应用是使得 Amdahl 定律代替摩尔定律成为计算机性能发展源动力的根本原因,也是人类“压榨”计算机运算能力的最有力武器。
12.1 概述
多任务处理在现代计算机操作系统中几乎已是一项必备的功能了;除了充分利用计算机处理器的能力外,一个服务端同时对多个客户端提供服务则是另一个更具体的并发应用场景。
12.2 硬件的效率与一致性
基于高速缓存的存储交互很好地解决了处理器与内存的速度矛盾,但是也引入了一个新的问题:缓存一致性。为了解决一致性的问题,需要各个处理器访问缓存时都遵循一些协议,在读写时要根据协议来进行操作,这类协议有 MSI、MESI、MOSI、Synapse、Firefly 及 Dragon Protocol 等。
12.3 Java 内存模型
Java 虚拟机规范中视图定义一种 Java 内存模型(JMM)来屏蔽掉各种硬件和操作系统的内存访问差异,以实现让 Java 程序在各种平台下都能达到一致的内存访问效果。
12.3.1 主内存与工作内存
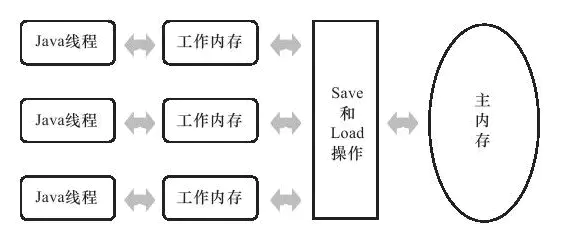
Java 内存模型的主要目标是定义程序中各个变量的访问规则,即在虚拟机中将变量存储到内存和从内存中取出变量这样的底层细节。此处的变量与 Java 编程中所说的变量有所区别,它包括了实例字段、静态字段和构成数组对象的元素,但不包括局部变量与方法参数,因为后者是线程私有的,不会被共享;
Java 内存模型规定了所有的变量都存储在主内存中,每个线程还有自己的工作内存,线程的工作内存中保存了被该线程使用到的变量的主内存副本拷贝,线程对变量的所有操作都必须在工作内存中进行,而不能直接读写主内存中的变量。线程、主内存和工作内存的关系如下所示:
12.3.2 内存间交互操作
主内存与工作内存之间具体的交互协议,即一个变量如何从主内存拷贝到工作内存、从工作内存同步回主内存之类的实现细节,Java 内存模型中定义了以下 8 种操作来完成:
Lock(锁定):作用于主内存的变量,将主内存该变量标记成当前线程私有的,其他线程无法访问它把一个变量标识为一条线程独占的状态。
Unlock(解锁):作用于主内存的变量,把一个处于锁定状态的变量释放出来,才能被其他线程锁定。
Read(读取):作用于主内存的变量,把一个变量的值从主内存传输到线程的工作内存中,以便随后的 load 动作使用。
Load(加载):作用于工作内存中的变量,把 read 操作从内存中得到的变量值放入工作内存的变量副本中。
Use(使用):作用于工作内存中的变量,把工作内存中一个变量的值传递给执行引擎,每当虚拟机遇到一个需要使用到变量的值的字节码指令时将会执行这个操作。
Assgin(赋值):作用于工作内存中的变量,把一个从执行引擎接收到的值赋值给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作。
Store(存储):作用于工作内存中的变量,把工作内存中一个变量的值传递到主内存中,以便随后的 write 操作使用。
Write(写入):作用于主内存中的变量,把 store 操作从工作内存中得到的变量的值放入主内存的变量中。
12.3.3 对于 volatile 型变量的特殊规则
关键字 volatile 可以说是 Java 虚拟机提供的最轻量级的同步机制。
当一个变量定义为 volatile 之后,它将具备两种特性:第一是保证此变量对所有线程的可见性,这里的可见性是指当一个线程修改了这个变量的值,新的值对于其他线程来说是可以立即得知的,而普通的变量的值在线程间传递均需要通过主内存来完成;另外一个是禁止指令重排序优化,普通的变量仅仅会保证在该方法的执行过程中所有依赖赋值结果的地方都能获取到正确的结果,而不能保证变量赋值操作的顺序与程序代码中的执行顺序一致;volatile 变量不保证原子性。
java 内存模型中对 volatile 变量定义的特殊规则。假定 T 表示一个线程,V 和 W 分别表示 volatile 型变量,那么在进行 read、load、use、assign、store 和 write 操作时需要满足如下规则:
1)只有当线程 T 对变量 V 执行的前一个动作为 load 时,T 才能对 V 执行 use;并且,只有 T 对 V 执行的后一个动作为 use 时,T 才能对 V 执行 load。T 对 V 的 use,可以认为是和 T 对 V 的 load。read 动作相关联,必须连续一起出现(这条规则要求在工作内存中,每次使用 V 前都必须先从主内存刷新最新的值,用于保证能看见其他线程对 V 修改后的值)。
2)只有当 T 对 V 的前一个动作是 assign 时,T 才能对 V 执行 store;并且,只有当 T 对 V 执行的后一个动作是 store 时,T 才能对 V 执行 assign。T 对 V 的 assign 可以认为和 T 对 V 的 store、write 相关联,必须连续一起出现(这条规则要求在工作内存中,每次修改 V 后都必须立刻同步回主内存中,用于保证其他线程看到自己对 V 的修改)。
3)假定动作 A 是 T 对 V 实施的 use 或 assign 动作,假定动作 F 是和动作 A 相关联的 load 或 store 动作,假定动作 P 是和动作 F 相应的对 V 的 read 或 write 动作;类似的,假定动作 B 是 T 对 W 实施的 use 或 assign 动作,假定动作 G 是和动作 B 相关联的 load 或 store 动作,假定动作 Q 是和动作 G 相应的对 W 的 read 或 write 动作。如果 A 先于 B,那么 P 先于 Q(这条规则要求 volatile 修饰的变量不会被指令的重排序优化,保证代码的执行顺序与程序的顺序相同)。
12.3.4 对 long 和 double 型变量的特殊规则
允许虚拟机将没有被 volatile 修饰的 64 位数据类型(long 和 double)的读取操作划分为两次 32 位的操作来进行,即允许虚拟机实现选择可以不保证 64 位数据类型的 load、store、read 和 write 这 4 个操作的原子性,就点就是 long 和 double 的非原子协定(Nonatomic Treatment of double and long Variables)。
12.3.5 原子性、可见性和有序性
** 原子性(Atomicity)**:由 Java 内存模型来直接保证的原子性变量操作包括 read、load、assign、use、store 和 write,我们大致可以认为基本数据类型的访问具备原子性(long 和 double 例外)。如果应用场景需要一个更大范围的原子性保证,Java 内存模型还提供了 lock 和 unlock 操作来满足需求,尽管虚拟机未把 lock 和 unlock 操作直接开放给用户,但是却提供了更高层次的字节码指令 monitorenter 和 monitorexit 来隐式地使用这两个操作,这两个字节码指令反应到 Java 代码中就是同步块——synchronized 关键字,因此在 synchronized 块之间的操作也具备原子性。
可见性(Visibility):指当一个线程修改了共享变量的值,其他线程能够立即得知这个修改。除了 volatile,Java 还有两个关键字能实现可见性,synchronized 和 final。
有序性(Ordering):Java 程序中天然的有序性可以总结为一句话:如果在本线程内观察,所有的操作都是有序的;如果在一个线程中观察另外一个线程,所有的操作都是无序的。Java 语言提供了 volatile 和 synchronized 两个关键字来保证线程之间操作的有序性。
12.3.6 先行发生原则
1)程序次序规则(Program Order Rule):在一个线程内,按照程序代码顺序,书写在前面的操作先行发生于书写在后面的操作。准确地来说应该是控制流顺序而不是程序代码顺序,因为要考虑分支 / 循环结构。
2)管程锁定规则(Monitor Lock Rule):一个 unlock 操作先行发生于后面对同一锁的 lock 操作。这里必须强调的是同一锁,而“后面”是指时间上的先后顺序。
3)volatile 变量规则(Volatile Variable Rule):对一个 volatile 变量的写操作先行发生于后面对这个变量的读操作,这里的“后面”是指时间上的先后顺序。
4)线程启动规则(Thread Start Rule):Thread 对象的 start() 方法先行发生于此线程的每一个动作。
5)线程终止规则(Thread Termination Rule):线程中的所有操作都先行发生于对此线程的终止检测,我们可以通过 Thread.join()方法结束 /Thread.isAlive() 的返回值等手段检测到县城已经终止执行。
6)线程中断规则(Thread Interruption Rule):对线程 interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生,可以通过 Thread.interrupted() 方法检测到是否有中断发生。
7)对象终结规则(Finalizer Rule):一个对象的初始化完成(构造函数执行结束)先行发生于它的 finalize() 方法的开始。
8)传递性(Transitivity):如果操作 A 先行发生于操作 B,操作 B 先行发生于操作 C,那么操作 A 先行发生于操作 C。
12.4 Java 与线程
并发不一定依赖多线程,但是 Java 里面谈论并发,大多数与线程脱不开关系。
12.4.1 线程的实现
主流操作系统都提供了线程实现,Java 语言则提供了在不同硬件和操作系统平台对线程的同一处理,每个 java.lang.Thread 类的实例就代表了一个线程。Thread 类与大部分 Java API 有着显著的差别,它的所有关键方法都被声明为 Native。在 Java API 中一个 Native 方法可能就意味着这个方法没有使用或无法使用平台无关的手段实现。
实现线程主要三种方式:
1. 使用内核线程实 2. 使用用户线程实现 3. 使用用户线程加轻量级进程混合实现
12.4.2 Java 线程调度
线程调度是指系统为线程分配处理器使用权的过程,主要调度方式有两种,分别是协同式线程调度(线程的执行时间由线程本身来控制)和抢占式线程调度(线程由系统来分配执行时间,线程的切换不由线程本身来决定);
Java 语言一共设置了 10 个级别的线程优先级,不过线程优先级并不是太靠谱,原因就是操作系统的线程优先级不见得总是与 Java 线程的优先级一一对应,另外优先级还可能被系统自行改变;
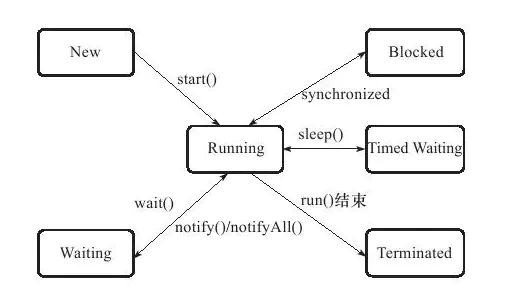
12.4.3 状态转换
Java 语言定义了五种线程状态,在任意一个时间点,一个线程只能有且只有其中一种状态,分别是新建(New)、运行(Runnable)、无限期等待(Waiting)、限期等待(Timed Waiting)、阻塞(Blocled)、结束(Terminated)。它们之间相互的转换关系如下所示:
第 13 章 线程安全与锁优化
13.1 概述
首先需要保证并发的正确性,然后在此基础上实现高效;
13.2 线程安全
当多个线程访问一个对象时,如果不用考虑这些线程在运行时环境下的调度和交替执行,也不需要进行额外的同步,或者在调用方进行任何其他的协调操作,调用这个对象的行为都可以获得正确的结果,那这个对象是线程安全的。
13.2.1 Java 语言中的线程安全
我们可以将 Java 语言中各个操作共享的数据分为以下五类:不可变、绝对线程安全、相对线程安全、线程兼容和线程对立;
不可变:不可变带来的安全性是最简单和最纯粹的,如 final 的基本数据类型;如果共享的数据是一个对象,那就需要保证对象的行为不会对其状态产生任何影响才行,比如 String 类的 substring、replace 方法;Number 类型的大部分子类都符合不可变要求的类型,但是 AtomicInteger 和 AtomicLong 则并非不可变的;
线程绝对安全:Java API 中标注自己是线程安全的类,大多数都不是绝对的线程安全;比如 java.util.Vector,不意味着调用它的是时候永远都不再需要同步手段了;
线程相对安全:是我们通常意义上所讲的线程安全,在 Java 语言中,大部分的线程安全类都属于这种类型;
线程兼容:指对象本身并不是线程安全的,但是可以通过在调用端正确地使用同步手段来保证对象在并发环境中可以安全地使用;我们说一个类不是线程安全的,绝大多数时候指的是这一种情况;
线程对立:无论调用端是否采取了同步措施,都无法在多线程环境中并发使用的代码,Java 语言中很少出现;
13.2.2 线程安全的实现方法
互斥同步:同步是指在多个线程并发访问共享数据时,保证共享数据在同一个时刻只被一个线程使用,而互斥是实现同步的一种手段,临界区、互斥量和信号量都是主要的互斥实现方式;Java 中最基本的互斥同步手段就是 synchronized 关键字,它对同一个线程来说是可重入的且会阻塞后面其他线程的进入;另外还可以使用 java.util.concurrent 包中的重入锁(ReentrantLock)来实现同步,相比 synchronized 关键字 ReentrantLock 增加了一些高级功能:等待可中断、可实现公平锁以及锁可以绑定多个条件;
非阻塞同步:互斥同步最主要的问题就是进行线程阻塞和唤醒带来的性能问题,其属于一种悲观的并发策略;随着硬件指令集的发展,我们有了另外一个选择即基于冲突检测的乐观并发策略,就是先进行操作,如果没有其他线程争用共享数据那就操作成功了,如果有争用产生了冲突,那就再采取其他的补偿措施(最常见的就是不断重试直至成功),这种同步操作称为非阻塞同步;Java 并发包的整数原子类,其中的 compareAndSet 和 getAndIncrement 等方法都使用了 Unsafe 类的 CAS 操作;
无同步方案:要保证线程安全,并不是一定就要进行同步;有一些代码天生就是线程安全的,比如可重入代码和线程本地存储的代码;
13.3 锁优化
锁优化技术:适应性自旋、锁销除、锁粗化、轻量级锁、偏向锁,这些技术都为了在线程之间更加高效地共享数据,以及解决竞争问题,从而提高程序的执行效率。
13.3.1 自旋锁与自适应自旋
互斥同步对性能最大的影响是阻塞的实现,挂起线程和恢复线程的操作都需要转入内核态中完成,这些操作给系统的并发性能带来了很大的压力;另外在共享数据的锁定状态只会持续很短的一段时间,为了这段时间去挂起和恢复线程并不值得,如果让两个或以上的线程同时并行执行,让后面请求锁的那个线程稍等一下,但不放弃处理器的执行时间,看看持有锁的线程是否很快就会释放锁;为了让线程等待,我们只需让线程执行一个忙循环,这些技术就是所谓的自旋锁;
在 JDK 1.6 已经默认开启自旋锁;如果锁被占用的时间很短自旋等待的效果就会非常好,反之则会白白消耗处理器资源;
在 JDK 1.6 中引入了自适应的自旋锁,这意味着自旋的时间不再固定,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定;
13.3.2 锁消除
锁消除是指虚拟机即时编译器在运行时,对一些代码上要求同步,但是被检测到不可能存在共享数据竞争的锁进行消除;锁消除的主要判断依据来源于逃逸分析的数据支持。
13.3.3 锁粗化
原则上总是推荐将同步块的作用范围限制得尽量小 – 只有在共享数据的实际作用域中才进行同步,这样是为了使得需要同步的操作数量尽可能变小,如果存在锁竞争,那等待锁的线程也能尽快拿到锁;
但是如果一系列的连续操作都对同一个对象反复加锁和解锁,甚至加锁操作是出现在循环体中的,那即使没有线程竞争,频繁地进行互斥同步操作也会导致不必要的性能损耗;
13.3.4 轻量级锁
要理解轻量级锁,以及后面会讲到的偏向锁的原理和运作过程,必须从 HotSpot 虚拟机的对象的内存布局开始介绍;HotSpot 虚拟机的对象头分为两部分信息:第一部分用于存储对象自身的运行时数据,如哈希码、GC 分代年龄等,这部分官方称之为Mark Word,是实现轻量级锁和偏向锁的关键;另外一部分用于存储指向方法区对象类型数据的指针:
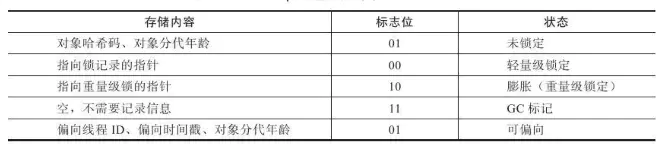
在代码进入同步块的时候,如果此同步对象没有被锁定,虚拟机首先将在当前线程的栈帧中建立一个名为锁记录(Lock Record)的空间,用于存储对象目前的 Mark Word 的拷贝(官方称之为 Displaced Mark Word);然后虚拟机将使用 CAS 操作尝试将对象的 Mark Word 更新为指向 Lock Record 的指针,如果更新成功了那么这个线程就拥有了该对象的锁,并且对象 Mark Word 的锁标志位将转变为“00”,即表示此对象处于轻量级锁定状态;如果这个更新操作失败了,虚拟机首先会检查对象的 Mark Word 是否指向当前线程的栈帧,如果是就可以直接进入同步块继续执行,否则说明这个锁对象已经被其他线程抢占了;如果有两条以上的线程争用同一个锁,那轻量级锁就不再有效,要膨胀为重量级锁,锁标志的状态值变为“10”,Mark Word 中存储的就是指向重量级锁的指针,后面等待锁的线程也要进行阻塞状态。
13.3.5 偏向锁
偏向锁也是 JDK 1.6 中引入的一项锁优化,它的目的是消除数据在无竞争情况下的同步原语,进一步提高程序的运行性能;如果说轻量级锁是在无竞争的情况下使用 CAS 操作去消除同步使用的互斥量,那偏向锁就是在无竞争的情况下把整个同步都消除掉,连 CAS 操作都不做了;
偏向锁会偏向于第一个获得它的线程,如果在接下来的执行过程中,该锁没有被其他的线程获取,则持有偏向锁的线程将永远不需要再进行同步;
假设当前虚拟机启动了偏向锁,那么当锁对象第一次被线程获取的时候,虚拟机将会把对象头中的标志位设为“01”,即偏向模式;同时使用 CAS 操作把获取到这个锁的线程 ID 记录在对象的 Mark Word 之中;如果 CAS 操作成功,持有偏向锁的线程以后每次进入这个锁相关的同步块时,虚拟机都可以不再进行任何同步操作;当有另外一个线程去尝试获取这个锁时,偏向模式就宣告结束,根据锁对象目前是否被锁定的状态,撤销偏向后恢复到未锁定或轻量级锁定的状态,后续的同步操作就如上面介绍的轻量级锁那样执行;偏向锁、轻量级锁的状态转化以及对象 Mark Work 的关系如下图所示:

完结……
转载:https://www.jianshu.com/p/3eb07497b43a
作者:波波波先森